

|
“Everything about singing is organized around the ear; it is the superior regulator.” ~Alfred Tomatis |

Filtered Listening
Consider the profound capacity of human hearing. The ear separates all of the sounds in a given space into tiny component parts, and the ear and brain keep track of the intricate interactions of competing sounds in ways that boggle the mind. Remember a time when you’ve been in a crowded room and able to follow a conversation. Perhaps you were following multiple conversations? Think about all of the different frequencies that your ears and brain were following in that moment, and the specificity with which you were able to pay attention to them. Or, as Reiner Plomp says in The Intelligent Ear “perhaps the most striking property of the hearing system is its ability to analyze the world of superimposed sounds and to separate them according to their various sources” (pg 12). Until recently, human perception of sound was understood to contain the qualities of pitch, loudness, and timbre. Of these three elements, the first two have been widely studied and defined scientifically. Timbre is not only a vast concept compared to pitch and loudness, but it has become a loosely defined catch-all for human perception. Although artists have developed their own systems and terms for defining important timbral qualities in their own sounds, science has been slow to explore these elements in meaningful ways. Thanks to the work of Helmholtz, Tomatis, Plomp, Titze, Howell, Bozeman, Sundberg, Obert, and others, we have begun to understand timbre as a complicated sea of individual elements with discernible fields. When these elements are understood and promoted in our listening, they change the ways that we perceive sound. Ian Howell's Parsing The Spectral Envelope (2016) introduced a theoretical approach intended to expressly define timbre in smaller, scientifically measurable fields, and is most specifically related to the human voice. The following article builds on the goal of defining timbre through distinct elements, offering scientifically-measurable fields that can be accessed in theory and practice to engage the voice through guided listening.
Plomp, R. (2002). The intelligent ear: On the nature of sound perception. Mahwah, NJ: Lawrence Erlbaum Associates.
Consider the profound capacity of human hearing. The ear separates all of the sounds in a given space into tiny component parts, and the ear and brain keep track of the intricate interactions of competing sounds in ways that boggle the mind. Remember a time when you’ve been in a crowded room and able to follow a conversation. Perhaps you were following multiple conversations? Think about all of the different frequencies that your ears and brain were following in that moment, and the specificity with which you were able to pay attention to them. Or, as Reiner Plomp says in The Intelligent Ear “perhaps the most striking property of the hearing system is its ability to analyze the world of superimposed sounds and to separate them according to their various sources” (pg 12). Until recently, human perception of sound was understood to contain the qualities of pitch, loudness, and timbre. Of these three elements, the first two have been widely studied and defined scientifically. Timbre is not only a vast concept compared to pitch and loudness, but it has become a loosely defined catch-all for human perception. Although artists have developed their own systems and terms for defining important timbral qualities in their own sounds, science has been slow to explore these elements in meaningful ways. Thanks to the work of Helmholtz, Tomatis, Plomp, Titze, Howell, Bozeman, Sundberg, Obert, and others, we have begun to understand timbre as a complicated sea of individual elements with discernible fields. When these elements are understood and promoted in our listening, they change the ways that we perceive sound. Ian Howell's Parsing The Spectral Envelope (2016) introduced a theoretical approach intended to expressly define timbre in smaller, scientifically measurable fields, and is most specifically related to the human voice. The following article builds on the goal of defining timbre through distinct elements, offering scientifically-measurable fields that can be accessed in theory and practice to engage the voice through guided listening.
Plomp, R. (2002). The intelligent ear: On the nature of sound perception. Mahwah, NJ: Lawrence Erlbaum Associates.
The ear's complexity has neurological researchers curious to know more about the ear and how it interacts with the brain. The impact of the ear on the brain, including emotional, social, memory, mood, impact on the body such as posture and breathing, etc. are being studied, and yielding incredible results. But what about the impact of the ear on the voice? How does the profoundly facile sensory organ that is the ear relate to the voice?
One pioneer in auditory/neurological interaction (psychoacoustics) Alfred Tomatis, wrote that not only does the voice respond to the ear, but that the ear teaches the voice what to do. He says:
"Vocal emission is controlled by the ear."
"This law, that one can only deliberately produce a sound that falls within the limits of self-monitoring, and the functioning of that feedback loop, has been repeatedly verified in the laboratory. It establishes a reciprocal action between audition [ear] and phonation [voice] so they exactly match one another. Since then, I have used my discovery extensively in education, reeducation, remedial teaching, etc. . .It is easy to determine how a given singer hears by analyzing the frequencies that comprise his voice" (pg 28).
To our knowledge, Tomatis was the first to use filtered listening in a dedicated, focused manner. His approach was simpler than the one outlined in this article, but still led him to report astounding results.
Tomatis, Alfred A. The Ear and the Voice. Scarecrow Press, Inc. Maryland, 1987/2001.
One pioneer in auditory/neurological interaction (psychoacoustics) Alfred Tomatis, wrote that not only does the voice respond to the ear, but that the ear teaches the voice what to do. He says:
"Vocal emission is controlled by the ear."
"This law, that one can only deliberately produce a sound that falls within the limits of self-monitoring, and the functioning of that feedback loop, has been repeatedly verified in the laboratory. It establishes a reciprocal action between audition [ear] and phonation [voice] so they exactly match one another. Since then, I have used my discovery extensively in education, reeducation, remedial teaching, etc. . .It is easy to determine how a given singer hears by analyzing the frequencies that comprise his voice" (pg 28).
To our knowledge, Tomatis was the first to use filtered listening in a dedicated, focused manner. His approach was simpler than the one outlined in this article, but still led him to report astounding results.
Tomatis, Alfred A. The Ear and the Voice. Scarecrow Press, Inc. Maryland, 1987/2001.
The measured results of filtered listening open voice learning into some incredible opportunities. First, if a vocalist can perceive/self-monitor specific sounds (e.g. individual parts of sounds) then they can reproduce them, and conversely, if they aren't producing them, they likely are unaware of them. Tomatis' research also suggests that if vocalists maintain attention on the sounds they are interested in hearing in their voice, those individual parts of the sound will persist, becoming a trusted tool in their kit. Tomatis says: "This information applies equally to the singing and the speaking voice. From the moment that the ear starts to listen, and take control, the voice responds by becoming well modulated, rich in timbre, providing the nervous system with the kind of stimulation that it needs to do its work" (pg 129).
The Filtered Listening Questions
Two questions arise:
1. What is perception? In this instance, it is important to create separation between hearing in general, and hearing with distinction (what Tomatis calls "self-monitoring"). When a person speaks or sings, anyone listening will hear them. To discern the distinct elements of their sounds down to individual frequencies, however, takes intention. Perception for use in filtered listening involves listening with a level of distinction that includes individual frequencies or focused groups of frequencies. Awareness of how these individual frequencies influence the overall sound is a secondary aspect of perception.
The Filtered Listening Questions
Two questions arise:
1. What is perception? In this instance, it is important to create separation between hearing in general, and hearing with distinction (what Tomatis calls "self-monitoring"). When a person speaks or sings, anyone listening will hear them. To discern the distinct elements of their sounds down to individual frequencies, however, takes intention. Perception for use in filtered listening involves listening with a level of distinction that includes individual frequencies or focused groups of frequencies. Awareness of how these individual frequencies influence the overall sound is a secondary aspect of perception.
2. How do people learn to create the circumstances in which their ears and brains will open to this kind of perception?
The process of neurological differentiation known as filtered listening provides a detailed approach to defining and working with the ingredients of sound that contribute to the varied vocal qualities available to any vocalist. The VoiceScienceWorks ListenUP process is a reliable method for accessing a vocalist's rainbow of vocal potential.
Ian Howell describes this distinction by saying that "sound waves can be understood as instructions for timbre, not the timbre itself. The way in which the human hearing mechanism reacts to those instructions limits, colors, and in some cases creates aspects of the voice" (Necessary pg 4). . ." To best understand the whole of a sung vowel’s timbre, and to engage and analyze it according to its inherent properties, I believe we must break it apart into conceptual and perceptual units smaller than common sense suggests exist" (Parsing pg 17).
Or, as Igor Stravinsky quipped: “To listen is an effort, and just to hear is no merit. A duck hears also.”
Howell, Ian. "Necessary Roughness In Voice Pedagogy." VoicePrints: Journal of the New York Singing Teachers' Association. May-June 2017, pg 1-7.
Howell, Ian. Parsing The Spectral Envelope. Doctoral Dissertation, New England Conservatory, 2016.
The process of neurological differentiation known as filtered listening provides a detailed approach to defining and working with the ingredients of sound that contribute to the varied vocal qualities available to any vocalist. The VoiceScienceWorks ListenUP process is a reliable method for accessing a vocalist's rainbow of vocal potential.
Ian Howell describes this distinction by saying that "sound waves can be understood as instructions for timbre, not the timbre itself. The way in which the human hearing mechanism reacts to those instructions limits, colors, and in some cases creates aspects of the voice" (Necessary pg 4). . ." To best understand the whole of a sung vowel’s timbre, and to engage and analyze it according to its inherent properties, I believe we must break it apart into conceptual and perceptual units smaller than common sense suggests exist" (Parsing pg 17).
Or, as Igor Stravinsky quipped: “To listen is an effort, and just to hear is no merit. A duck hears also.”
Howell, Ian. "Necessary Roughness In Voice Pedagogy." VoicePrints: Journal of the New York Singing Teachers' Association. May-June 2017, pg 1-7.
Howell, Ian. Parsing The Spectral Envelope. Doctoral Dissertation, New England Conservatory, 2016.
“Anyone who endeavors for the first time to distinguish the upper partial tones of a musical tone, generally finds considerable difficulty in merely hearing them” (pg 7). ~Hermann von Helmholtz
Helmholtz, H.L.F. (1954). On the sensations of tones as the physiological basis for the theory of music (Trans. A.J. Ellis). New York: Dover (original work published 1863).
Helmholtz, H.L.F. (1954). On the sensations of tones as the physiological basis for the theory of music (Trans. A.J. Ellis). New York: Dover (original work published 1863).
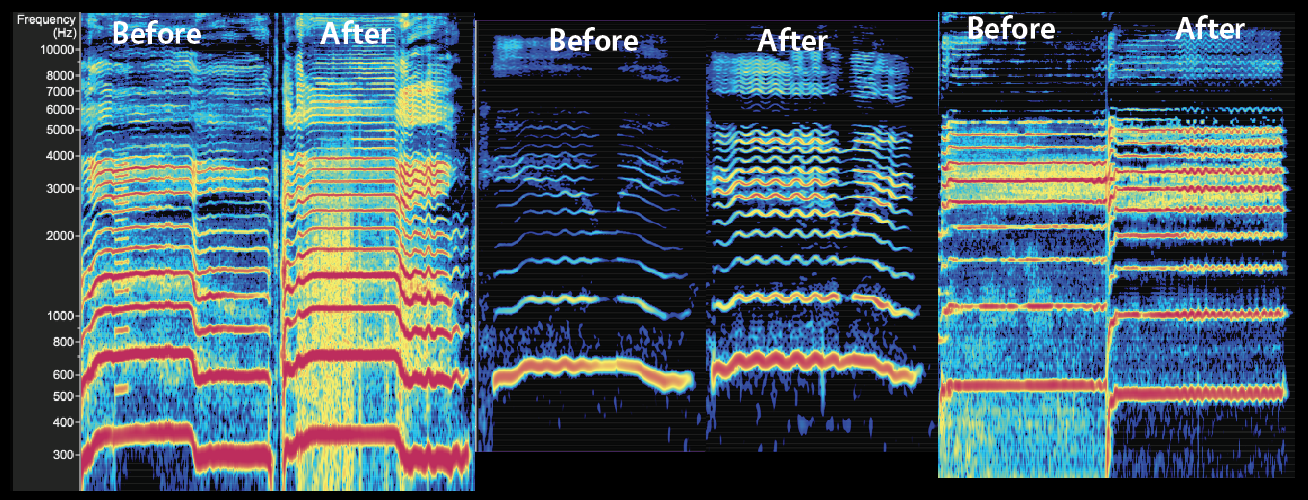
The ListenUP process relies on target practice combined with an objective understanding of sound elements to guide the voice through the use of the ear. In this image, the vocal signatures of three different vocalists changed significantly after only a week of guided, filtered listening. These vocalists, like most that we work with, were unaware of the harmonics present in their sound prior to experiencing filtered listening. Notice that in each, the intensity of the harmonics on the left increase in depth of color and intensity in addition to becoming sharper and more defined.
The VoiceScienceWorks ListenUP Filtered Listening Process
To begin with, here are the steps involved in the VoiceScienceWorks ListenUP process.
1. Record the target sound (or find a recording of a target sound)
2. Choose harmonics to focus on in the target sound and filter them using a filter function found in an overtone analyzer software like Voce Vista Video (see below for ways to determine which sounds to filter)
3. Do the following with ear-covering headphones as the filtered target recording plays:
a. Listen 3 times to the filtered region(s)
b. While continuing to listen, vocalize 3 times along with a straw
c. Vocalize 3 times along without a straw
-while singing with the headphones, learning to listen to the recording as if it is "your voice" rather than trying to hear the sound coming from your actual voice is essential
4. Without the headphones, vocalize listening for the filtered harmonics in the air
Note: we also have explored approaches to filtered listening that don't rely on software, but have found that having a voice analyzer software with a filter function like Voce Vista profoundly increases the ear's capacity to influence the voice.
To begin with, here are the steps involved in the VoiceScienceWorks ListenUP process.
1. Record the target sound (or find a recording of a target sound)
2. Choose harmonics to focus on in the target sound and filter them using a filter function found in an overtone analyzer software like Voce Vista Video (see below for ways to determine which sounds to filter)
3. Do the following with ear-covering headphones as the filtered target recording plays:
a. Listen 3 times to the filtered region(s)
b. While continuing to listen, vocalize 3 times along with a straw
c. Vocalize 3 times along without a straw
-while singing with the headphones, learning to listen to the recording as if it is "your voice" rather than trying to hear the sound coming from your actual voice is essential
4. Without the headphones, vocalize listening for the filtered harmonics in the air
Note: we also have explored approaches to filtered listening that don't rely on software, but have found that having a voice analyzer software with a filter function like Voce Vista profoundly increases the ear's capacity to influence the voice.
Traditional Language and Auditory Perception
Traditional vocal pedagogy tends to rely on binaries for comparison. Vocalists are encouraged to choose between, for example: bright/dark, head/chest, front/back, loud/soft, etc. By contrast to an either/or scenario, a person’s vocal signature contains a rainbow of opportunities in every moment.
Traditional vocal pedagogy tends to rely on binaries for comparison. Vocalists are encouraged to choose between, for example: bright/dark, head/chest, front/back, loud/soft, etc. By contrast to an either/or scenario, a person’s vocal signature contains a rainbow of opportunities in every moment.
In this video, a vocalist was asked to sing ten different versions of what someone might call “head voice”. Notice how differently they all appear in a spectrogram, how different parts of the sound are missing or promoted in each version in only ten possible examples. With such diversity of ingredients, how can all of these examples be labeled by the same term with any hope of meaningful distinction? The voice is the most diverse instrument on the planet, and can create such a wide variety of sounds that learning to discern the differences between such an array of options can create incredible difficulty. This has led traditional language about the voice to create binaries. Instead of learning to embrace the rainbow of options available to each voice, vocal instruction has tended toward creating a world of black and white language like "head voice" and "chest voice".
Traditional Language As A Series of Binaries

Consider some traditional language popular in today’s voice studio. Singers are asked to respond to language as if they are dialing a nob that only has two options, or asked to understand them as points on either end of an undefined "spectrum." Confusion can often persist while vocalists consciously try to decipher their colorful sound with limited options.
Hearing the Rainbow
What are the important ingredients in a vocal signature, on what are they based, and how can vocalists learn to focus them in their hearing? When speaking about all of the muscular, psychological, emotional, airflow, and acoustic elements at play in a given vocalization, the ingredients begin to stack up pretty quickly and can seem overwhelming. Returning to the ears, however, focusing on the ingredients in the sound itself makes the complex job of singing much simpler. The "sound" is, after all, a culmination of all of individual sonic elements that go into making complex sound. Focusing on sonic ingredients guides the ear to teach the voice. Importantly, when employing filtered listening, the voice adjusts to the demands of the ear and brain. Once the voice adjusts in response to the ear, interested vocalists can begin to explore other variables involved in those changes. Rather than trying to ask someone to adjust the muscles of their larynx or sing a metaphoric concept, for example, allowing the ear to guide the voice to make a discovery and then discussing how laryngeal muscles or language may have had an impact on the sound creates opportunities for curiosity and exploration. Most importantly, the vocalist has the opportunity to respond directly to sound without anyone else's ideas getting in their way.
What are the important ingredients in a vocal signature, on what are they based, and how can vocalists learn to focus them in their hearing? When speaking about all of the muscular, psychological, emotional, airflow, and acoustic elements at play in a given vocalization, the ingredients begin to stack up pretty quickly and can seem overwhelming. Returning to the ears, however, focusing on the ingredients in the sound itself makes the complex job of singing much simpler. The "sound" is, after all, a culmination of all of individual sonic elements that go into making complex sound. Focusing on sonic ingredients guides the ear to teach the voice. Importantly, when employing filtered listening, the voice adjusts to the demands of the ear and brain. Once the voice adjusts in response to the ear, interested vocalists can begin to explore other variables involved in those changes. Rather than trying to ask someone to adjust the muscles of their larynx or sing a metaphoric concept, for example, allowing the ear to guide the voice to make a discovery and then discussing how laryngeal muscles or language may have had an impact on the sound creates opportunities for curiosity and exploration. Most importantly, the vocalist has the opportunity to respond directly to sound without anyone else's ideas getting in their way.
"The human body is full of oscillations of tissue, air, fluids, electric waves, sound waves, light waves, and free-floating particles. We have our brains to thank for being able to deal with all these multiple oscillators (neural, mechanical, and acoustic), and so to straighten out what would otherwise be a hopeless chaotic instrument. To accomplish this, the brain needs inputs – particularly sound inputs. This leads us to the voice-ear connection." (pg 26) ~Ingo Titze
Titze, I. R. (2010). Fascinations with the human voice. Salt Lake City, UT: NCVS, National Center for Voice and Speech.
Titze, I. R. (2010). Fascinations with the human voice. Salt Lake City, UT: NCVS, National Center for Voice and Speech.
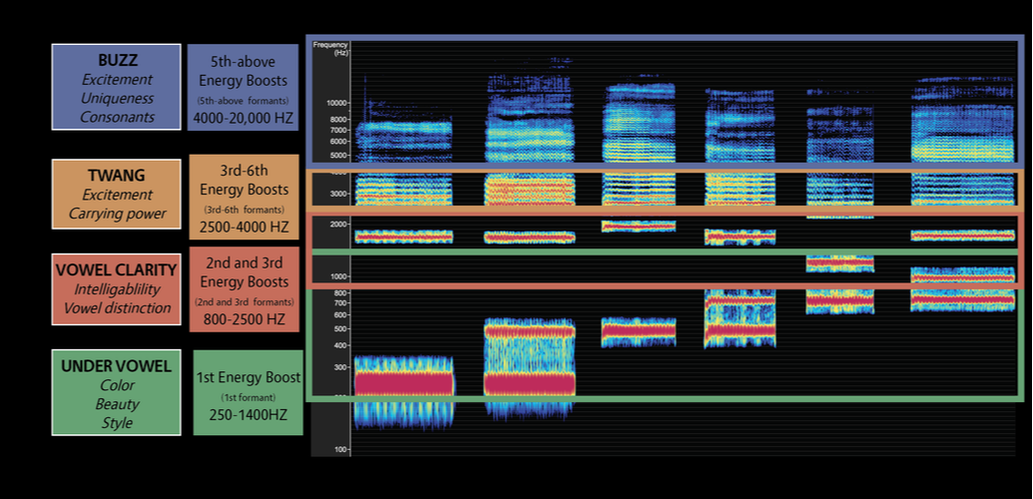
Four Vocal Regions
We have found it most effective to break down the vocal signature into four vocal regions that, when the harmonics within them are focused in the ear, can bring unique and important qualities out in the voice. We have chosen to call these regions: Buzz Region, Twang Region, Vowel Clarity Region, and Under Vowel Region. The reasons for these particular terms and the articulation of unique qualities inherent within each region are based on the work of a number of researchers, and in our own research and practice. They will be described below in greater detail.
We have found it most effective to break down the vocal signature into four vocal regions that, when the harmonics within them are focused in the ear, can bring unique and important qualities out in the voice. We have chosen to call these regions: Buzz Region, Twang Region, Vowel Clarity Region, and Under Vowel Region. The reasons for these particular terms and the articulation of unique qualities inherent within each region are based on the work of a number of researchers, and in our own research and practice. They will be described below in greater detail.
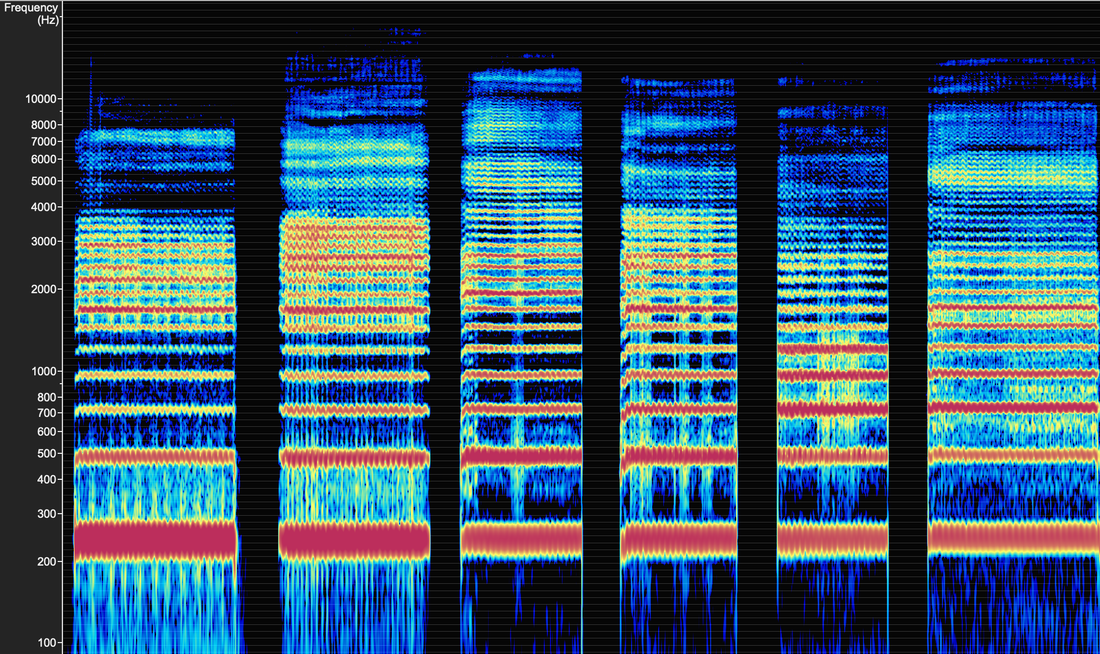
In this spectrogram image using Voce Vista, a vocalist sings a C4 (256Hz) on an [i] vowel chain ([i] [I] {e] [ɛ] [a] [æ]...sounds like "beet, bit, bay, bet, bot, bat"). The sound has been filtered to highlight where the energy boosts (formants) interact with the harmonics. Notice how starting with the third vowel, for example, the fundamental (first harmonic) is no longer present. That is because the first energy boost (first formant) has moved to the second harmonic for the [e] vowel shape. We, therefore, filtered out (eliminated) the harmonics that are not aligned with the energy boosts (formants) of that region. The Four Vocal Regions of Buzz, Twang, Vowel Clarity, and Under Vowel are labeled on the left hand side of the image.
|
The four vocal regions are determined by
1) how and where the energy boosts of the vocal tract (known as formants) interact with 2) the harmonics produced when the vocal folds come into contact, and 3) how the ear/brain perceives that information. Formants in Brief: Formants are a complex scientific concept that can be understood both as a physical manifestation and a sonic result, and have direct influence on people's perception of sound. For the sake of this article, we are most focused on the sonic result, and therefore are calling them "energy boosts." Note that energy troughs are also a result of formants, but for the sake of this article, we consider the troughs to be more or less negative space. To speak in simplistic terms, the vocal tract has countless pockets of air in it that change shape as the jaw, tongue, etc. move around (physical). Some of these pockets are as large as the vocal tract itself, and some are quite tiny (physical). As these pockets of air change shape, they either amplify certain harmonics or depress certain harmonics (sonic). Therefore, these mobile energy boosts each have some influence on the way sound from the voice is heard and felt. Because the vocal tract changes shape, these pockets of air change shape, and by doing so, change the frequencies that they boost. The largest pockets of air (the lowest formants) have the greatest influence on human perception of voiced sound, with the lowest pitched seven or eight being the most traceable (perception). Titze and Verdolini Abbott describe the frequent use of the first two energy boosts alone to define sound by saying that "We have shown only two formant frequencies..., F1 and F2, although there is theoretically an infinite number" (pg 295). (Read more about formants and harmonics) Titze, Ingo and Verdolini Abbott, Katherine. Vocology: The Science and Practice of Voice Habilitation. National Center For Voice and Speech. Salt Lake City, UT, 2012. |
In this spectrogram video using Voce Vista, a vocalist vocal fries an [i] vowel chain and then sings a C4 (256Hz) on an [i] vowel chain ([i] [I] {e] [ɛ] [a] [æ]...sounds like "beet, bit, bay, bet, bot, bat"). Because a vocal fry doesn't have a harmonic series, it can be used to see the energy boosts (formants) of the vocal tract isolated from the harmonics that result from the vocal folds. In the sung part of the video, the sound has been filtered to highlight where the energy boosts (formants) interact with the harmonics. Notice how starting with the third vowel, for example, the fundamental (first harmonic) is no longer present. That is because the first energy boost (first formant) has moved to the second harmonic for the [e] vowel shape. The Four Vocal Regions of Buzz, Twang, Vowel Clarity, and Under Vowel are represented.
|
The vocal tract has countless pockets of air that create energy boosts when aligned with harmonics from the vocal folds.
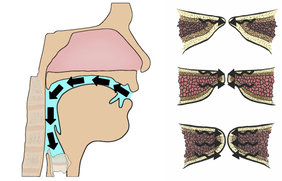
Acoustic energy returning to the vocal folds is essential for vocal fold vibration. The nature of acoustic feedback encourages the vocal folds into different vibration patterns.
|
What happens inside of the vocal tract is incredibly important to voiced sound for a number of reasons. Firstly, the vocal tract is the last part of the voicing system (starting with breath) before sound is heard, giving it influence over the sound itself. Also, whatever occurs in the vocal tract feeds back to the vocal folds, and influences how they vibrate. Depending on the resonant strategy, the vocal folds are encouraged to vibrate in certain ways, leading the muscles of the vocal folds to respond. This also means that acoustic feedback from the vocal tract heavily influences breath. When acoustic support is most efficient, the vocal folds are most efficient, thereby maximizing on the amount of air being used to phonate. Titze and Verdolini Abbott say that "inertive reactance in the supraglottal vocal tract [energy feeding the vocal folds] helps vocal fold vibration, whereas compliant supraglottal reactance [no energy to feed the vocal folds] hinders vocal fold vibration. This is the essence of resonant versus non-resonant voice! One objective, therefore, in obtaining a resonant voice is to increase inertive reactance in the supraglottal tract at many frequencies to gain maximum assistance for vocal fold vibration" (pg 296).
Each sound region (Under Vowel, Vowel Clarity, Twang, and Buzz) are determined by specific energy boosts (formants) of the vocal tract. Learning to hear and respond to each of them helps to "gain maximum assistance for vocal fold vibration" (pg 296). Titze, Ingo and Verdolini Abbott, Katherine. Vocology: The Science and Practice of Voice Habilitation. National Center For Voice and Speech. Salt Lake City, UT, 2012. |
"If the upper partials are removed from auditory control, the voice will model itself on the lower band. It gets lower. When the lows are suppressed, you will see the highs light up on the response curve" (pg 92). ~Alfred Tomatis
Tomatis, Alfred A. The Ear and the Voice. Scarecrow Press, Inc. Maryland, 1987/2001.
Tomatis, Alfred A. The Ear and the Voice. Scarecrow Press, Inc. Maryland, 1987/2001.
The Under Vowel Region
The first energy boost (first formant) determines the first region of sound that we call the Under Vowel Region. The energy boost (formant) that influences the Under Vowel Region is the lowest pitched and strongest of all of the energy boosts (formants). This lowest/strongest energy boost (formant) aligns with the harmonics with the most energy.
note: the Under Vowel doesn’t boost frequencies below around 250HZ, though people can sing much lower than that. Therefore, as a sung scale descends past 250HZ the Under Vowel relates to higher harmonics.
The term "Under Vowel" derives from the work of Kenneth W. Bozeman: Kinesthetic Voice Pedagogy. Inside View Press, 2017. Bozeman's use of the term is somewhat different than our use here, as our use of Under Vowel as a region contrasts to a somewhat more focused use in his work.
The first energy boost (first formant) determines the first region of sound that we call the Under Vowel Region. The energy boost (formant) that influences the Under Vowel Region is the lowest pitched and strongest of all of the energy boosts (formants). This lowest/strongest energy boost (formant) aligns with the harmonics with the most energy.
note: the Under Vowel doesn’t boost frequencies below around 250HZ, though people can sing much lower than that. Therefore, as a sung scale descends past 250HZ the Under Vowel relates to higher harmonics.
The term "Under Vowel" derives from the work of Kenneth W. Bozeman: Kinesthetic Voice Pedagogy. Inside View Press, 2017. Bozeman's use of the term is somewhat different than our use here, as our use of Under Vowel as a region contrasts to a somewhat more focused use in his work.

The [i] vowel chain filtered to highlight the harmonics most boosted in the Under Vowel Region.
This image of an [i] vowel chain has been filtered for the Under Vowel Region (the lowest energy boost also known as the first formant). The Under Vowel can range from around 250HZ to about 1400HZ, though most people tend to have an Under Vowel range of 250-1000HZ. People tend to move their Under Vowel around quickly and with ease across this frequency range. The quickly moving Under Vowel is an essential ingredient in vowel creation for speech. Singers often learn to stabilize the Under Vowel to maximize on its varying potential to create stability, strength, color, and beauty (as perceived within a given style).
The image below shows the original, unfiltered, recording of the [i] vowel chain sung at C4 (256Hz). Notice how the visual represents that the Under Vowel moves upward through the course of the vowel chain. The evidence of this rests in which of the lowest harmonics is the boldest red and thickest. Compare the full harmonic image below to the filtered image above, and track the changes in the first energy boost (formant) across the vowel chain. Learning to identify where the first energy boost (formant) sits in comparison to the lowest harmonics is essential in determining filters for listening.
The image below shows the original, unfiltered, recording of the [i] vowel chain sung at C4 (256Hz). Notice how the visual represents that the Under Vowel moves upward through the course of the vowel chain. The evidence of this rests in which of the lowest harmonics is the boldest red and thickest. Compare the full harmonic image below to the filtered image above, and track the changes in the first energy boost (formant) across the vowel chain. Learning to identify where the first energy boost (formant) sits in comparison to the lowest harmonics is essential in determining filters for listening.
The unfiltered [i] vowel chain.
|
|
In this spectrogram recording, a vocalist sings a C4 (256Hz) on an [i] vowel chain ([i] [I] {e] [ɛ] [a] [æ]...sounds like "beet, bit, bay, bet, bot, bat") followed by an [u] vowel chain ([u] [ʊ] [o] [ɔ] [a] [æ]...sounds like "boot, book, boat, bought, bot, bat"). The sound has been filtered to highlight only the first energy boost (first formant) and where it interacts with the harmonics. Since the recording is filtered for the first energy boost, the fundamental disappears on the third vowel shape. This is because the first energy boost is aligned with higher harmonics in these moments. Notice that the two vowel chains sound almost identical in this recording. In fact, the first vowel chain is the [i] vowel chain, but it doesn't sound like those vowels at all. One of the auditory illusions of human voice sound creation is that the [i] and [u] first energy boost are identical, as is true on up the vowel chain. This reality creates significant phonation opportunities.
|
In the above image, the Under vowel moves from its lowest position around 250Hz through the stair steps that make up the vowel chain. For some of the vowel shapes sung at C4, the Under Vowel aligns with a single harmonic, while for other vowel shapes the Under Vowel aligns between two harmonics. When the Under Vowel aligns with the first harmonic, a "Whoop" resonant strategy occurs. When the Under Vowel aligns with the second harmonic or above, a "Hey" resonant strategy occurs. When the Under Vowel aligns in between two harmonics, an "Acoustic Mix" resonant strategy occurs. Each of these Under Vowel resonant strategies influences vocal fold vibration and auditory perception, making them essential elements of consideration for style, color, beauty, power, and stability.
The terms "whoop" and "hey" derive from the work of Kenneth Bozeman: Practical Vocal Acoustics. Bozeman has been an exemplary voice in the valuable work of imbuing traditional vocal pedagogy terminology and concepts with contemporary voice science understanding. In reference to under vowel resonant strategies, he uses the term "yell" instead of "hey". His use of the term "yell" has slightly different purposes than our use of the term "hey." Importantly, he speaks of this second harmonic/first energy boost (formant) coupling as a primal sound, and reserves the term only for the second harmonic/first energy boost (formant) coupling compared to our use of "hey" for any first energy boost/harmonic coupling beginning with the second harmonic and rising. He addresses the concept of "acoustic mix" in a different way, referring to "close" and "open" vowels as a result of the first energy boost moving around the first two harmonics, and "passive vowel modification" as a result of vocal tract stability that, when sung across multiple pitches can result in more occasions of what we have termed "acoustic mix". Another important perceptual aspect of Bozeman's "passive vowel modification" is a timbral change that results in a change in vowel quality as pitch changes occur through a stable vocal tract shape. "Acoustic mix" as a resonant strategy concept defines the distinct "in between" relationship between the first energy boost (formant) and any two harmonics. Bozeman defines "close" as: "The frequency of the first formant also determines the openness or closeness of a vowel. Close vowels such as /i/ or /u/ have low first formants. Open Vowels such as /ɛ/, /ɔ/, or /a/ have high first formants. Therefore the higher the formant the more open the vowel, the lower the formant the closer the vowel" (pg 14). He defines "passive vowel modification" as "whenever a source harmonic passes through the first formant there is an audible effect (some degree of closing or opening of the timbre with an accompanying, simultaneous passive vowel modification), which is perceivable as an acoustic registration phenomenon" (pg 15). On our acoustic strategies page, we explore some of the challenges with using the "open" and "close" traditional language, and why we feel that terms like "acoustic mix" and "hey" are helpful new terms.
Bozeman, Kenneth W. Practical Vocal Acoustics. Pendragon Press, Hilsdale, NY, 2013.
The terms "whoop" and "hey" derive from the work of Kenneth Bozeman: Practical Vocal Acoustics. Bozeman has been an exemplary voice in the valuable work of imbuing traditional vocal pedagogy terminology and concepts with contemporary voice science understanding. In reference to under vowel resonant strategies, he uses the term "yell" instead of "hey". His use of the term "yell" has slightly different purposes than our use of the term "hey." Importantly, he speaks of this second harmonic/first energy boost (formant) coupling as a primal sound, and reserves the term only for the second harmonic/first energy boost (formant) coupling compared to our use of "hey" for any first energy boost/harmonic coupling beginning with the second harmonic and rising. He addresses the concept of "acoustic mix" in a different way, referring to "close" and "open" vowels as a result of the first energy boost moving around the first two harmonics, and "passive vowel modification" as a result of vocal tract stability that, when sung across multiple pitches can result in more occasions of what we have termed "acoustic mix". Another important perceptual aspect of Bozeman's "passive vowel modification" is a timbral change that results in a change in vowel quality as pitch changes occur through a stable vocal tract shape. "Acoustic mix" as a resonant strategy concept defines the distinct "in between" relationship between the first energy boost (formant) and any two harmonics. Bozeman defines "close" as: "The frequency of the first formant also determines the openness or closeness of a vowel. Close vowels such as /i/ or /u/ have low first formants. Open Vowels such as /ɛ/, /ɔ/, or /a/ have high first formants. Therefore the higher the formant the more open the vowel, the lower the formant the closer the vowel" (pg 14). He defines "passive vowel modification" as "whenever a source harmonic passes through the first formant there is an audible effect (some degree of closing or opening of the timbre with an accompanying, simultaneous passive vowel modification), which is perceivable as an acoustic registration phenomenon" (pg 15). On our acoustic strategies page, we explore some of the challenges with using the "open" and "close" traditional language, and why we feel that terms like "acoustic mix" and "hey" are helpful new terms.
Bozeman, Kenneth W. Practical Vocal Acoustics. Pendragon Press, Hilsdale, NY, 2013.
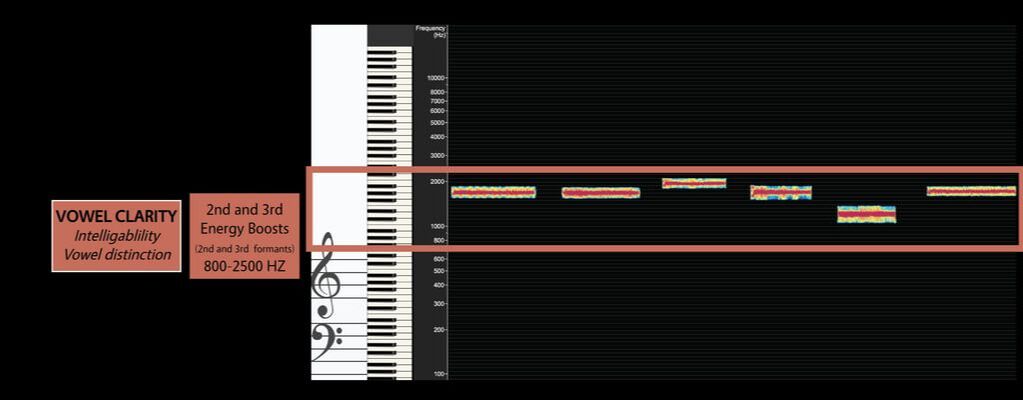
Vowel Clarity Region
The second region of sound, the Vowel Clarity Region, is determined by the second and sometimes third energy boosts (2nd and 3rd formants). This region results from the next two lowest energy boosts of the vocal tract, and therefore represents a strong influence on the way we hear and feel sound. The Vowel Clarity Region ranges from around 800HZ to around 2500HZ. Although the Vowel Clarity Region overlaps the Under Vowel Region, the energy boosts will never cross over one another due to physical restrictions. As Bozeman says: "Although both the first and second formants [energy boosts] participate in defining a vowel, the second formant [energy boost] is perceptually more responsible for clarity of definition" (pg 15).
Bozeman, Kenneth W. Practical Vocal Acoustics. Pendragon Press, Hilsdale, NY, 2013.
The second region of sound, the Vowel Clarity Region, is determined by the second and sometimes third energy boosts (2nd and 3rd formants). This region results from the next two lowest energy boosts of the vocal tract, and therefore represents a strong influence on the way we hear and feel sound. The Vowel Clarity Region ranges from around 800HZ to around 2500HZ. Although the Vowel Clarity Region overlaps the Under Vowel Region, the energy boosts will never cross over one another due to physical restrictions. As Bozeman says: "Although both the first and second formants [energy boosts] participate in defining a vowel, the second formant [energy boost] is perceptually more responsible for clarity of definition" (pg 15).
Bozeman, Kenneth W. Practical Vocal Acoustics. Pendragon Press, Hilsdale, NY, 2013.
The [i] vowel chain filtered to highlight the harmonics most boosted in the Vowel Clarity Region.
 The unfiltered version of the [i] vowel chain
The unfiltered version of the [i] vowel chain
This image of an [i] vowel chain has been filtered for the Vowel Clarity Region. The second energy boost highlights a single harmonic on each of the six vowel shapes at the upper part of the Vowel Clarity region. Thanks to the discovery of Absolute Spectral Tone Color, we now know that people hear vowel as pitch, that is, each frequency within the human hearing range has a vowel-like color. Most of the frequencies that people perceive as vowel appear in the Vowel Clarity region, hence the name. The characteristic “whistle” sound of overtone singing results from this region as well, and listening specifically for the frequencies in the Vowel Clarity Region will often sound like listening to distinct whistles. The individual most associated with defining absolute spectral tone color (ASTC) is Ian Howell. To read more of his ground breaking work, and see his videos, visit his website.
Tomatis noticed in his reading of Helmholtz's acoustics research in the 19th century that Helmholtz "classified each vowel as belonging to a fixed note" (Ear and Voice pg 108). Fifty years later, Tomatis says, Koenig describes specific ranges of pitches that contained specific vowel colors (Ear and Voice pg 108). In 2016, Ian Howell, making note that another luminary, William Vennard, noticed a similar reality in 1967, gave this curious relationship between vowel and timbre the name "absolute spectral tone color (ASTC)." He defines it as such:
"Any two or more simple sounds (e.g. a sine wave, single harmonic of a complex tone, or narrowly notch filtered band of noise) of identical frequency, regardless of their sources, will produce an identical tone color percept independent of other spectral fluctuations considered aspects of timbre. If these simple sounds are located within a complex sound, their inherent absolute spectral tone color is never lost or changed, only expressed or masked. These tone colors may be placed on a continuum, and bear a meaningful similarity to several vowels" (Parsing pg 29-30).
Awareness of the unique vowel-like sound of distinct frequency groupings, and the reality that they don't change, but are merely promoted or depressed in our awareness based on the intensity of other frequencies becomes a new powerful entry point into sound perception. Since most of these unique vowel-like colors exist in the Vowel Clarity Region, the region has distinct qualities even beyond the corresponding energy boosts (formants). Importantly, frequencies below 500Hz tend to all sound like different versions of ~u, and frequencies above 2300Hz tend to all sound like different versions of ~i. All other vowel-like qualities are contained between 500-2300Hz. Howell suggests the use the "~" symbol instead of brackets "[i]" or slashes "/i/" typically used to denote complex combinations of frequencies that yield a composite "eeee" sound. He says: "To label ASTC, I use the ‘~’ followed by a letter. This indicates that a sine tone at that frequency elicits a quality of the dominant tone color of the sound indicated by the letter when used in the International Phonetics Alphabet" (Necessary pg 5).
Howell, Ian. Parsing The Spectral Envelope. Doctoral Dissertation, New England Conservatory, 2016 for more detailed explanation of absolute spectral tone color.
William Vennard, Singing: The Mechanism and the Technic (New York: Carl Fischer, 1967).
Tomatis, Alfred A. The Ear and the Voice. Scarecrow Press, Inc. Maryland, 1987/2001.
Howell, Ian. "Necessary Roughness In Voice Pedagogy." VoicePrints: Journal of the New York Singing Teachers' Association. May-June 2017, pg 1-7.
Tomatis noticed in his reading of Helmholtz's acoustics research in the 19th century that Helmholtz "classified each vowel as belonging to a fixed note" (Ear and Voice pg 108). Fifty years later, Tomatis says, Koenig describes specific ranges of pitches that contained specific vowel colors (Ear and Voice pg 108). In 2016, Ian Howell, making note that another luminary, William Vennard, noticed a similar reality in 1967, gave this curious relationship between vowel and timbre the name "absolute spectral tone color (ASTC)." He defines it as such:
"Any two or more simple sounds (e.g. a sine wave, single harmonic of a complex tone, or narrowly notch filtered band of noise) of identical frequency, regardless of their sources, will produce an identical tone color percept independent of other spectral fluctuations considered aspects of timbre. If these simple sounds are located within a complex sound, their inherent absolute spectral tone color is never lost or changed, only expressed or masked. These tone colors may be placed on a continuum, and bear a meaningful similarity to several vowels" (Parsing pg 29-30).
Awareness of the unique vowel-like sound of distinct frequency groupings, and the reality that they don't change, but are merely promoted or depressed in our awareness based on the intensity of other frequencies becomes a new powerful entry point into sound perception. Since most of these unique vowel-like colors exist in the Vowel Clarity Region, the region has distinct qualities even beyond the corresponding energy boosts (formants). Importantly, frequencies below 500Hz tend to all sound like different versions of ~u, and frequencies above 2300Hz tend to all sound like different versions of ~i. All other vowel-like qualities are contained between 500-2300Hz. Howell suggests the use the "~" symbol instead of brackets "[i]" or slashes "/i/" typically used to denote complex combinations of frequencies that yield a composite "eeee" sound. He says: "To label ASTC, I use the ‘~’ followed by a letter. This indicates that a sine tone at that frequency elicits a quality of the dominant tone color of the sound indicated by the letter when used in the International Phonetics Alphabet" (Necessary pg 5).
Howell, Ian. Parsing The Spectral Envelope. Doctoral Dissertation, New England Conservatory, 2016 for more detailed explanation of absolute spectral tone color.
William Vennard, Singing: The Mechanism and the Technic (New York: Carl Fischer, 1967).
Tomatis, Alfred A. The Ear and the Voice. Scarecrow Press, Inc. Maryland, 1987/2001.
Howell, Ian. "Necessary Roughness In Voice Pedagogy." VoicePrints: Journal of the New York Singing Teachers' Association. May-June 2017, pg 1-7.
|
|
In this spectrogram recording, a vocalist sings a C4 (256Hz) on an [i] vowel chain ([i] [I] {e] [ɛ] [a] [æ]...sounds like "beet, bit, bay, bet, bot, bat") followed by an [u] vowel chain ([u] [ʊ] [o] [ɔ] [a] [æ]...sounds like "boot, book, boat, bought, bot, bat"). The sound has been filtered to highlight only the second energy boost (second formant), and where interacts with the harmonics produced by the vocal folds. Since the recording is filtered for the second energy boost, only the harmonics that are boosted by the second energy boost appear. These are sometimes more than 1000Hz above the fundamental frequency. Notice that each frequency has a vowel-like color, but that these vowel-like colors aren't the same as the vowel shape being sung. One of the auditory illusions of human voice sound creation is that the frequencies utilized to create complex vowel sounds are not identical to the frequencies that sound like the complex vowel. This reality creates significant phonation opportunities, particularly where vowel modification is concerned.
|
Critical Bandwidth and The Vowel Clarity Region
As frequencies within the harmonic series get closer and closer together, they eventually combine into clusters of sound past what is known as the "critical bandwidth". After this point, humans struggle to hear the harmonics as distinct frequencies. Howell defines the resulting "roughness" in the following way: "Generally, any two simple tones a minor third or closer will give rise to such roughness; the closer, the rougher. . .for much of the singable range, the minor third is a useful, if simplified rule. . .From the fifth harmonic (H5) and up, all harmonics of a voice fall within a minor third (within the critical band) of a neighbor" (pg 4).
Within a harmonic series, therefore, above the fifth harmonic, individuals begin to hear harmonics as clusters of sounds that have ever-increasing "roughness". However, by focusing the vocal tract through the use of energy boosts, and training the ear on specific harmonics, all of the harmonics that fall within the vowel clarity region can be promoted and therefore heard as distinctly individual frequencies. This is the basis of the art of overtone singing, and can be a powerful tool in training the voice. Within the Vowel Clarity Region, the second and third energy boosts have the capacity to work together to promote individual harmonics. This can be done in a radical way, like in overtone singing, or in ways that integrate the promoted harmonics more into the whole of the sound. Learning to hear and play with promoting these harmonics can create profound opportunities for uniqueness, stability, and color in the voice.
Note that low bass singing creates the opportunity for closer harmonic clusters within the Vowel Clarity Region, which allows for buzzy clusters to be promoted the Vowel Clarity Region. This is a reason why low bass notes in ensembles create such an enriching effect. Equally, high singing (higher on the treble clef staff and above) creates the opposite reality, where the "critical bandwidth" occurs within or above the Twang Region, yielding different opportunities.
Howell, Ian. "Necessary Roughness In Voice Pedagogy." VoicePrints: Journal of the New York Singing Teachers' Association. May-June 2017, pg 1-7.
As frequencies within the harmonic series get closer and closer together, they eventually combine into clusters of sound past what is known as the "critical bandwidth". After this point, humans struggle to hear the harmonics as distinct frequencies. Howell defines the resulting "roughness" in the following way: "Generally, any two simple tones a minor third or closer will give rise to such roughness; the closer, the rougher. . .for much of the singable range, the minor third is a useful, if simplified rule. . .From the fifth harmonic (H5) and up, all harmonics of a voice fall within a minor third (within the critical band) of a neighbor" (pg 4).
Within a harmonic series, therefore, above the fifth harmonic, individuals begin to hear harmonics as clusters of sounds that have ever-increasing "roughness". However, by focusing the vocal tract through the use of energy boosts, and training the ear on specific harmonics, all of the harmonics that fall within the vowel clarity region can be promoted and therefore heard as distinctly individual frequencies. This is the basis of the art of overtone singing, and can be a powerful tool in training the voice. Within the Vowel Clarity Region, the second and third energy boosts have the capacity to work together to promote individual harmonics. This can be done in a radical way, like in overtone singing, or in ways that integrate the promoted harmonics more into the whole of the sound. Learning to hear and play with promoting these harmonics can create profound opportunities for uniqueness, stability, and color in the voice.
Note that low bass singing creates the opportunity for closer harmonic clusters within the Vowel Clarity Region, which allows for buzzy clusters to be promoted the Vowel Clarity Region. This is a reason why low bass notes in ensembles create such an enriching effect. Equally, high singing (higher on the treble clef staff and above) creates the opposite reality, where the "critical bandwidth" occurs within or above the Twang Region, yielding different opportunities.
Howell, Ian. "Necessary Roughness In Voice Pedagogy." VoicePrints: Journal of the New York Singing Teachers' Association. May-June 2017, pg 1-7.
The Twang Region
The Twang Region includes the third to the sixth energy boosts (3rd-6th formants), depending on the resonant strategy, and includes the harmonics between 2500-4000Hz. Much research has been done on the Twang Region's acoustic benefits. In Principles Of Voice Production, Ingo Titze points to this vocal region as key to producing an unamplified vocal sound that can be heard over a full orchestra, and that can carry across a large space (Principles pg 265). Johann Sundberg referred to this region as the “Singer’s Formant Cluster” in his Science of the Singing Voice (Science pg 101). Early use of the word "twang" appears in Sir Richard Paget's Human Speech. Paget was trying to determine what made American accents different from British ones, and mentioned "twang" as one element. Thanks to researchers like Jo Estill, the term “twang” has come into general usage when referring to the perceptual results of this region and/or slightly above. Singers who are able to amplify this band of sound energy experience ease and excitement in their sound, a sensation described as “getting volume for free.”
In the 2017 International Journal of Listening article “The Effects of the Tomatis Method on the Artistic Voice,” the authors described this band as being responsible for “…higher intelligibility in the speaker who is able to produce clearer sounds. The improvement in the perception on the frequencies around 3 kHz has an effect on the speech power, on the color of the voice and on its expressive power. A voice rich in high harmonics is a voice with a wide range of emotional expressions” (Effects pg 119). Further, the 2,500-4,000 Hz frequency band represents a region of the vocal signature that creates a desirable timbre for most singers and speakers and appears significantly in many vocalization styles.
Titze, Ingo. Principles of Voice Production. National Center of Voice And Speech, Iowa, 2000.
Sundberg, Johan. Science of the Singing Voice. Northern Illinois Press, 1987.
Stillitano, Rosati, Cisternino, Fioretti, Iaconelli, & Eibenstein. (2017). "The Effects of the Tomatis Method on the Artistic Voice." International Journal of Listening, 31 (2), 113-120.
Paget, Richard. (1930). Human Speech. New York, NY: Kegan Paul, Trench, Trubner and Co.
The Twang Region includes the third to the sixth energy boosts (3rd-6th formants), depending on the resonant strategy, and includes the harmonics between 2500-4000Hz. Much research has been done on the Twang Region's acoustic benefits. In Principles Of Voice Production, Ingo Titze points to this vocal region as key to producing an unamplified vocal sound that can be heard over a full orchestra, and that can carry across a large space (Principles pg 265). Johann Sundberg referred to this region as the “Singer’s Formant Cluster” in his Science of the Singing Voice (Science pg 101). Early use of the word "twang" appears in Sir Richard Paget's Human Speech. Paget was trying to determine what made American accents different from British ones, and mentioned "twang" as one element. Thanks to researchers like Jo Estill, the term “twang” has come into general usage when referring to the perceptual results of this region and/or slightly above. Singers who are able to amplify this band of sound energy experience ease and excitement in their sound, a sensation described as “getting volume for free.”
In the 2017 International Journal of Listening article “The Effects of the Tomatis Method on the Artistic Voice,” the authors described this band as being responsible for “…higher intelligibility in the speaker who is able to produce clearer sounds. The improvement in the perception on the frequencies around 3 kHz has an effect on the speech power, on the color of the voice and on its expressive power. A voice rich in high harmonics is a voice with a wide range of emotional expressions” (Effects pg 119). Further, the 2,500-4,000 Hz frequency band represents a region of the vocal signature that creates a desirable timbre for most singers and speakers and appears significantly in many vocalization styles.
Titze, Ingo. Principles of Voice Production. National Center of Voice And Speech, Iowa, 2000.
Sundberg, Johan. Science of the Singing Voice. Northern Illinois Press, 1987.
Stillitano, Rosati, Cisternino, Fioretti, Iaconelli, & Eibenstein. (2017). "The Effects of the Tomatis Method on the Artistic Voice." International Journal of Listening, 31 (2), 113-120.
Paget, Richard. (1930). Human Speech. New York, NY: Kegan Paul, Trench, Trubner and Co.
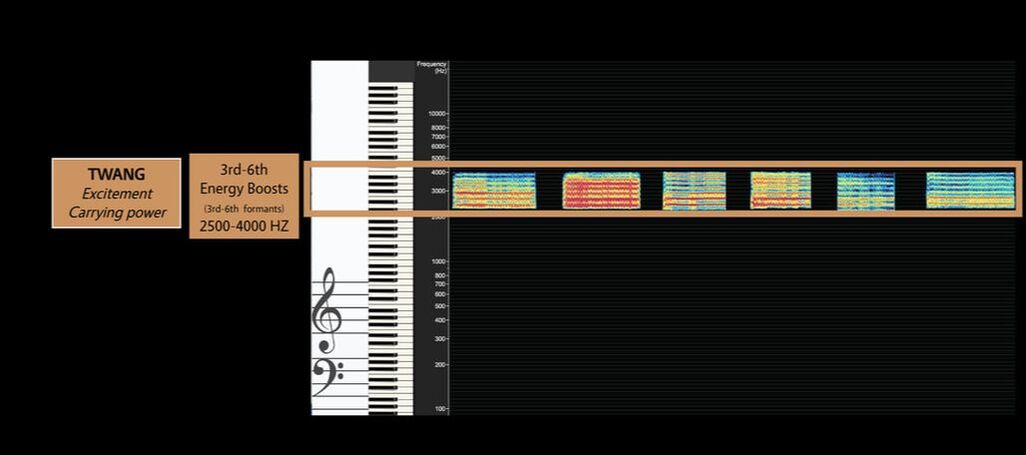
The [i] vowel chain filtered to highlight the harmonics most active in the Twang Region.
 The unfiltered version of the [i] vowel chain
The unfiltered version of the [i] vowel chain
This image of an [i] vowel chain has been filtered for the Twang Region. Unlike the Under Vowel and Vowel Clarity Regions, the Twang Region has a unique relationship with the auditory canal, and therefore, aural perception. Because the epilarynx tube, the part of the vocal tract most responsible for boosting sound in the Twang Region, is the same size as the ear canal, frequencies inhabiting the Twang Region get an extra boost. Although we refer to 2500-4000Hz as a region of information, there are many different resonant strategies available for accessing the Twang Region. Note how in the simple [i] vowel chain above, the resonant strategies used in the Twang Region vary.
Titze also describes physical alterations needed to increase amplitude in the Twang Region. A small area of the vocal tract just above the vocal folds (called the epilarynx tube) must narrow enough so that the ratio between the epilarynx tube and the pharynx is 1:6 (Principles pg 265). Such a ratio has no direct sensational equivalent, meaning that vocalists have no way of consciously aligning this critical physical ratio. As has been shown in other studies cited above, however, focused listening can guide the body to trigger the physical adjustments needed to create amplification in the Twang Region.
Titze goes on to explain this ratio, saying that "The small resonator (quarter wave) [the epilarynx tube] is bounded by the rim of the epiglottis at the open and and by the glottis at the closed end. . .there is a critical ratio of areas that seems to generate the approximate 3,000 Hz formant. The exact frequency is determined by the effective acoustic length of the small resonator [epilarynx tube]" (Principles pg 266).
Most importantly, though, in Vocology, he and Verdolini Abbott underscore that "Vocalists have little sensory awareness of the size of the cross sectional area of their epilarynx tube. Adjustments are mainly made on the basis of the perception of vocal ring (around 2500-3500Hz), which occurs when there is a sudden expansion from the epilarynx tube into a wide pharynx" (Vocology pg 300).
Titze, Ingo. Principles of Voice Production. National Center of Voice And Speech, Iowa, 2000.
Titze, Ingo and Katherine Verdolini Abbott. Vocology: The Science and Practice of Voice Habilitation. National Center For Voice and Speech. Salt Lake City, UT, 2012.
Titze also describes physical alterations needed to increase amplitude in the Twang Region. A small area of the vocal tract just above the vocal folds (called the epilarynx tube) must narrow enough so that the ratio between the epilarynx tube and the pharynx is 1:6 (Principles pg 265). Such a ratio has no direct sensational equivalent, meaning that vocalists have no way of consciously aligning this critical physical ratio. As has been shown in other studies cited above, however, focused listening can guide the body to trigger the physical adjustments needed to create amplification in the Twang Region.
Titze goes on to explain this ratio, saying that "The small resonator (quarter wave) [the epilarynx tube] is bounded by the rim of the epiglottis at the open and and by the glottis at the closed end. . .there is a critical ratio of areas that seems to generate the approximate 3,000 Hz formant. The exact frequency is determined by the effective acoustic length of the small resonator [epilarynx tube]" (Principles pg 266).
Most importantly, though, in Vocology, he and Verdolini Abbott underscore that "Vocalists have little sensory awareness of the size of the cross sectional area of their epilarynx tube. Adjustments are mainly made on the basis of the perception of vocal ring (around 2500-3500Hz), which occurs when there is a sudden expansion from the epilarynx tube into a wide pharynx" (Vocology pg 300).
Titze, Ingo. Principles of Voice Production. National Center of Voice And Speech, Iowa, 2000.
Titze, Ingo and Katherine Verdolini Abbott. Vocology: The Science and Practice of Voice Habilitation. National Center For Voice and Speech. Salt Lake City, UT, 2012.
|
People who employ different vocal styles access the Twang Region in different ways. There are multiple approaches to creating resonant strategies with the energy boosts within this region of harmonics. Because of the importance of this region of harmonics to vocalists, a number of ways of describing the frequencies found within the Twang Region have surfaced over time. The "Twang Region," "Singers Formant Cluster," "ring," "ping," and "twang" all refer to a similar bandwidth of frequencies and a similar timbral quality. Each term, however, also all has unique differences from the anothers in the ways in which people use it, as is a common challenge with language choices.
In defining the four vocal regions, we have chosen to discuss the 2500-4000Hz band of frequencies as a region of sounds. They are distinguished by these frequency band's relationship to the epilaryx tube in the vocal tract (physical), the perceptual significance of this frequency band (perception), and the importance of their presence in all styles of singing (sonic). Importantly, 1500Hz is a rather wide band of frequencies. Because as many as four different energy boosts (formants) play active roles in this region, the ways in which vocalists utilize the harmonics within the Twang Region varies widely based on their stylistic desires. The difference between the "singer's formant" and the Twang Region has to do with function. Initial researchers into the Twang Region were focused on operatic singing, and noticed that male operatic singers clustered their upper energy boosts (formants) in a way that they focused significant energy into a smaller band of frequencies. To Bartholomew, that band of frequencies existed around 3,000HZ, for Sundberg, it was allowed to range across 2,500-4,000Hz, but was always specific to a more narrow band. Sundberg saw the energy boosts clustering, and made the suggestion that the clustering of the energy boosts created a new formant, when in reality he was noticing the increased energy that arises from the clustering of energy boosts (formants). He called this "new formant" the "singer's formant". Importantly, Sundberg’s “Singers Formant” is a concept that relates specifically to the coupling of energy boosts (formants) in this region, but doesn’t relate to the region as a whole. Therefore, the singer's formant is one possible way to organize energy boosts in the Twang Region. It tends to be used by male operatic singers, but not all male operatic singers, and not by all female opera singers. Sundberg, Johan. Science of the Singing Voice. Northern Illinois Press, 1987. The term twang has been used to describe the brightness of sound that results from boosting the frequencies within the Twang Region. For many, twang is a vocal color, and an element within the vocal tool kit. In this respect, twang as a color tends to be less specific to frequency range, and is therefore more difficult to articulate and access. Harmonics within the Twang Region will often possess the qualities that those who seek "twang" are referring, but by describing the measurable qualities of the Twang Region, vocalists can more easily articulate the specific variations of twang they are interested in producing. Kerri Obert is one researcher doing the important work of discovering what parts of the vocal tract anatomy engage to create different perceptual results. She has chosen to use the term "twang" to describe frequencies higher than 4000Hz, and "ring" to describe the frequencies within what we are calling the Twang Region. At 1.03.00 in her video blog "Vocal Tract Contributions To Ring and Twang" she says that "I’ve determined that twang and ring are different and that we produce them in different ways," and later at 1.22.30 she concludes "Twang is produced by a narrowing of the pharyngeal constrictors, and ring is produced by the tongue root and the dorsum pushing back." Her explanation of the use of the term "twang", as explored through MRI and laryngescopy continues at 1.06.30: |
In this spectrogram recording using Voce Vista, a vocalist sings a C4 (256Hz) on an [i] vowel chain ([i] [I] {e] [ɛ] [a] [æ]...sounds like "beet, bit, bay, bet, bot, bat") followed by an [u] vowel chain ([u] [ʊ] [o] [ɔ] [a] [æ]...sounds like "boot, book, boat, bought, bot, bat"). The sound has been filtered to highlight the Twang Region, a region of harmonics between 2500-4000Hz, typically boosted by the third to sixth energy boosts (3rd-6th formants). Since the recording is filtered for the Twang Region, only the harmonics that lie within this region are present. Notice that even though each frequency grouping has an ~i ("eeee") vowel-like color, if you let your ears open to them over time, you will hear the individual vowel complex of each recording shining through the bright, ~i quality, and even the fundamental will eventually become evident. One of the auditory illusions of human voice sound creation is that the the ear and brain are incredibly facile at filling in space for muted or lost frequencies. This reality creates significant phonation opportunities, and helps vocalists begin to understand the value of increasing energy into different parts of their sound.
"When we twang we tend to eliminate the pyriform sinuses because the pharyngeal walls squeeze in and those pyriform sinuses kind of get squished out of the way….The more narrowing, the more twangy, and the less narrowing the less twangy. . .when we twang we tend to get brightness energy from 2000Hz all the way up to the higher frequencies, we get a broad, bold box of increased spectral energy from 2000 to 4000, 5000, etc. and we might even perceive this as a kind of noise, particularly in a rock singer." That Obert uses terminology in slightly different ways illuminates the reality that the voice science community is still working to agree on terminology. That is one reason why using the ear is critical, as it eliminates the need to describe the phenomonon in words, and lets the vocalist respond to sound directly. That she has articulated similar auditory realities leads to two important elements: 1) that the relative energy increase that results most often within the Twang Region can appear instead in frequencies found in the lower part of the Buzz region (often between 4000-7000Hz), most typically when singing high notes (sonic) and 2) that certain parts of the vocal tract have direct influence over which pockets of air create the energy boosts (formants) of the vocal tract (physical). Obert's work, and others who are doing research on the impact of anatomy on sound perception, continues to lead to more focused definitions of perception, and more refined ways to access vocal tools. Obert, Kerri. Vocal Tract Contributions To Ring and Twang In Voice Qualities, getvocal-now.com January 2020. |

In this brief spectrogam image in Voce Vista of "Popular" from "Wicked," Kristin Chenoweth demonstrates how some vocalists utilize frequencies above the Twang Region in ways similar to how the Twang Region is most commonly utilized. Notice first that she is singing with accompaniment. The vocal signature is notably different than that of the instruments by the vibrato and stronger energy (darker red) across the harmonic signature. Notice how she has a strong energy band around 3000Hz in addition to another above 4000Hz, and that the energy remains strong until 5000Hz, well into the Buzz Region. Vocalists resonant strategies are flexible and variable. The four vocal regions demonstrate common usage. An exciting element of understanding common engagements with the sonic results of the four vocal regions comes in the form of discovering novel approaches for the voice.
The Buzz Region
The fourth region of sound, the Buzz Region, covers from around 4000HZ, just above the Twang Region, to the upper limits of human hearing, around 20,000HZ. The Buzz Region provides energy to the sound, creating a since of lift, excitement, and uniqueness. Many aspects of consonants also exist within the Buzz Region. The fifth energy boosts and above come into play here. Sometimes they spread out, creating more of an overall wash of sound, and sometimes vocalists focus these upper energy boosts in ways that resemble the focus sometimes found in the Vowel Clarity Region that represent important aural aspects of their resonant strategies. This can be especially true for singers who create sounds in their upper range, and especially in styles that use more vocal fold contact. Most sung and spoken sounds are low enough that the harmonics in the Buzz Region are beyond the “critical bandwidth”, thereby creating the tell-tale buzzy sound. Howell describes this by referencing the work of Vassilakis and Kendall as:
"All harmonics ascending from the fifth harmonic fall within the critical band of a neighbor. If multiple harmonics fall within a critical band, and especially if they are of near equally high amplitude, one perceives roughness, 'the buzzing, rattling auditory sensation accompanying narrow harmonic intervals,'* in the tone" (Parsing pg 39). All pitches except for notes with fundamentals that lie above the top of the treble clef staff exhibit this "buzzing" in the Buzz Region, which is the primary instigation for the name. For the notes that lie above the top of the treble clef staff, and therefore have individual harmonics that are discernible in the Buzz Region, they still maintain a buzzy quality. These individual harmonics will sound like the individual whistles of the Vowel Clarity Region, but will have a much brighter ~i-like vowel quality. That ~i-like quality at such high harmonics has a perceptual "buzziness" by comparision with individual harmonics articulated lower in the human hearing range. Therefore, regardless of whether frequencies within the Buzz Region are clustered with other frequencies or not, they still have a more "buzzy" quality to those found in lower regions.
See Howell, Ian. Parsing The Spectral Envelope. Doctoral Dissertation, New England Conservatory, 2016 for more detailed explanation of "absolute spectral tone color", or "absolute timbre".
*See the abstract to Pantelis N. Vassilakis and Roger A. Kendall, “Psychoacoustic and cognitive aspects of auditory roughness: definitions, models, and applications,” Proc. SPIE 7527, Human Vision and Electronic Imaging XV, 75270O (February 17, 2010): doi:10.1117/12.845457.
The fourth region of sound, the Buzz Region, covers from around 4000HZ, just above the Twang Region, to the upper limits of human hearing, around 20,000HZ. The Buzz Region provides energy to the sound, creating a since of lift, excitement, and uniqueness. Many aspects of consonants also exist within the Buzz Region. The fifth energy boosts and above come into play here. Sometimes they spread out, creating more of an overall wash of sound, and sometimes vocalists focus these upper energy boosts in ways that resemble the focus sometimes found in the Vowel Clarity Region that represent important aural aspects of their resonant strategies. This can be especially true for singers who create sounds in their upper range, and especially in styles that use more vocal fold contact. Most sung and spoken sounds are low enough that the harmonics in the Buzz Region are beyond the “critical bandwidth”, thereby creating the tell-tale buzzy sound. Howell describes this by referencing the work of Vassilakis and Kendall as:
"All harmonics ascending from the fifth harmonic fall within the critical band of a neighbor. If multiple harmonics fall within a critical band, and especially if they are of near equally high amplitude, one perceives roughness, 'the buzzing, rattling auditory sensation accompanying narrow harmonic intervals,'* in the tone" (Parsing pg 39). All pitches except for notes with fundamentals that lie above the top of the treble clef staff exhibit this "buzzing" in the Buzz Region, which is the primary instigation for the name. For the notes that lie above the top of the treble clef staff, and therefore have individual harmonics that are discernible in the Buzz Region, they still maintain a buzzy quality. These individual harmonics will sound like the individual whistles of the Vowel Clarity Region, but will have a much brighter ~i-like vowel quality. That ~i-like quality at such high harmonics has a perceptual "buzziness" by comparision with individual harmonics articulated lower in the human hearing range. Therefore, regardless of whether frequencies within the Buzz Region are clustered with other frequencies or not, they still have a more "buzzy" quality to those found in lower regions.
See Howell, Ian. Parsing The Spectral Envelope. Doctoral Dissertation, New England Conservatory, 2016 for more detailed explanation of "absolute spectral tone color", or "absolute timbre".
*See the abstract to Pantelis N. Vassilakis and Roger A. Kendall, “Psychoacoustic and cognitive aspects of auditory roughness: definitions, models, and applications,” Proc. SPIE 7527, Human Vision and Electronic Imaging XV, 75270O (February 17, 2010): doi:10.1117/12.845457.

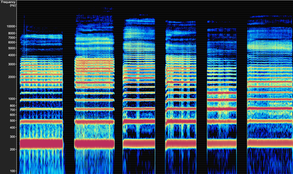
The [i] vowel chain filtered to highlight the harmonics most active in the Buzz Region.
 The unfiltered version of the [i] vowel chain
The unfiltered version of the [i] vowel chain
Vocalists often recoil from the buzzy sound of the Buzz Region. However, when guiding the ear toward the Buzz Region, vocalists learn to respond by bringing out individualistic, unique qualities in their sound that help them feel more full and energized. Equally, since many aspects of consonants exist in the Buzz Region, training consonants through filtered listening can create a sonic atmosphere that reinforces acoustic stability in lower frequency regions.
|
|
In this spectrogram recording, a vocalist sings a C4 (256Hz) on an [i] vowel chain ([i] [I] {e] [ɛ] [a] [æ]...sounds like "beet, bit, bay, bet, bot, bat") followed by an [u] vowel chain ([u] [ʊ] [o] [ɔ] [a] [æ]...sounds like "boot, book, boat, bought, bot, bat"). The sound has been filtered to highlight the Buzz Region, a region of harmonics between 4000-20,000Hz, typically boosted by the fifth energy boosts and above (5th formants and above). Since the recording is filtered for the Buzz Region, only the harmonics that lie within this region are present. Notice that even though each frequency grouping has an ~i ("eeee") vowel-like color, if you let your ears open to them over time, you will hear the individual vowel complex of each recording shining through the bright, ~i quality, and even the fundamental will eventually become evident. One of the auditory illusions of human voice sound creation is that the the ear and brain are incredibly facile at filling in space for muted or lost frequencies. This reality, called "the missing fundamental phenomenon" by Howell (pg 32), creates significant phonation opportunities, and helps vocalists begin to understand the value of increasing energy into different parts of their sound.
Howell, Ian. Parsing The Spectral Envelope. Doctoral Dissertation, New England Conservatory, 2016. |
The Four Regions and Absolute Spectral Tone Color
Absolute spectral tone color (ASTC) is a concept described by Ian Howell in Parsing the Spectral Envelope that explains how humans associate distinctive vowel-like colors with specific frequencies. Howell explains that people hear vowel as pitch, that is, that each frequency has a distinct vowel-like color. When these individual colors are combined, people hear complex vowel combinations. He says that "Two somewhat similar vowels may have near identical peak frequencies, and drastically different vowels may share peaks in common. This variability suggests that a vowel percept is the result of the total shape (the spectral envelope) rather than discrete content of its spectrum" (pg 9). These vowel complexes (and consonant complexes) are what people typically refer to as phonemes (vowels and consonants). Each of the four regions contains different combinations of these vowel-like colors. Learning to listen for them can create profound opportunities to access the benefits of each region.
Howell, Ian. Parsing The Spectral Envelope. Doctoral Dissertation, New England Conservatory, 2016.
Absolute spectral tone color (ASTC) is a concept described by Ian Howell in Parsing the Spectral Envelope that explains how humans associate distinctive vowel-like colors with specific frequencies. Howell explains that people hear vowel as pitch, that is, that each frequency has a distinct vowel-like color. When these individual colors are combined, people hear complex vowel combinations. He says that "Two somewhat similar vowels may have near identical peak frequencies, and drastically different vowels may share peaks in common. This variability suggests that a vowel percept is the result of the total shape (the spectral envelope) rather than discrete content of its spectrum" (pg 9). These vowel complexes (and consonant complexes) are what people typically refer to as phonemes (vowels and consonants). Each of the four regions contains different combinations of these vowel-like colors. Learning to listen for them can create profound opportunities to access the benefits of each region.
Howell, Ian. Parsing The Spectral Envelope. Doctoral Dissertation, New England Conservatory, 2016.
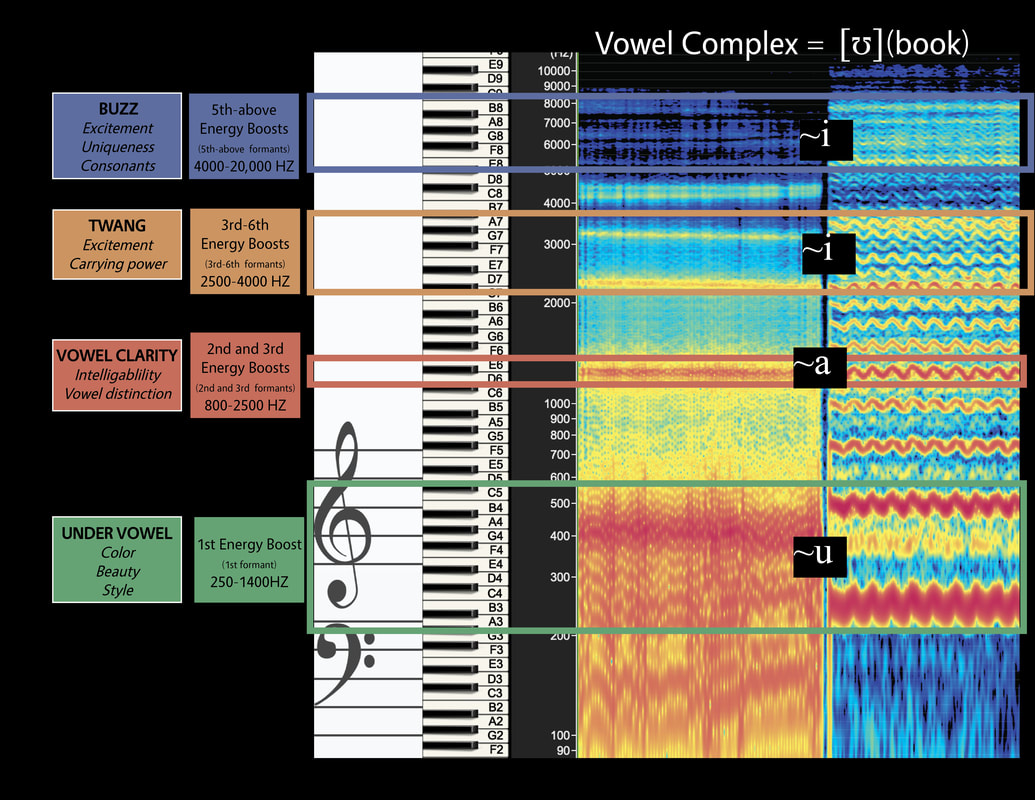
|
This image shows an [ʊ] vowel complex first produced through vocal fry (left). Vocal fry places the vocal folds into a unique posture the result of which is sound without a harmonic series. As such, vocal frying into a spectrogram will reveal the relative placement of each energy boost. Next to the vocal fry spectrogram image sits the same [ʊ] vowel shape sung on a C4 (256Hz). Notice that where the representation of the energy boosts in the vocal fry example exist, the harmonics to the right are energized (as seen through deepening red, intensity of brightness, and width). This shows how the energy boosts engage with harmonics. The absolute spectral tone color, vowel-like colors of each frequency is noted in little black boxes. The "~" symbol (described above) is used to distinguish between vowel complexes (denoted in brackets) and the individual vowel-like colors. Notice that the [ʊ] vowel complex is a combination of many different vowel-like colors.
|
In this spectrogram recording, a vocalist vocal fries an [i] vowel chain ([i] [I] {e] [ɛ] [a] [æ]...sounds like "beet, bit, bay, bet, bot, bat") followed by an [u] vowel chain ([u] [ʊ] [o] [ɔ] [a] [æ]...sounds like "boot, book, boat, bought, bot, bat"). The sound has been filtered to highlight the four vocal regions of the Under Vowel, Vowel Clarity, Twang, and Buzz Regions. Because the vocalist is using vocal fry, the vocal folds are not producing and overtone series. This allows the viewer to see the results of the energy boosts (formants) within each region.
|
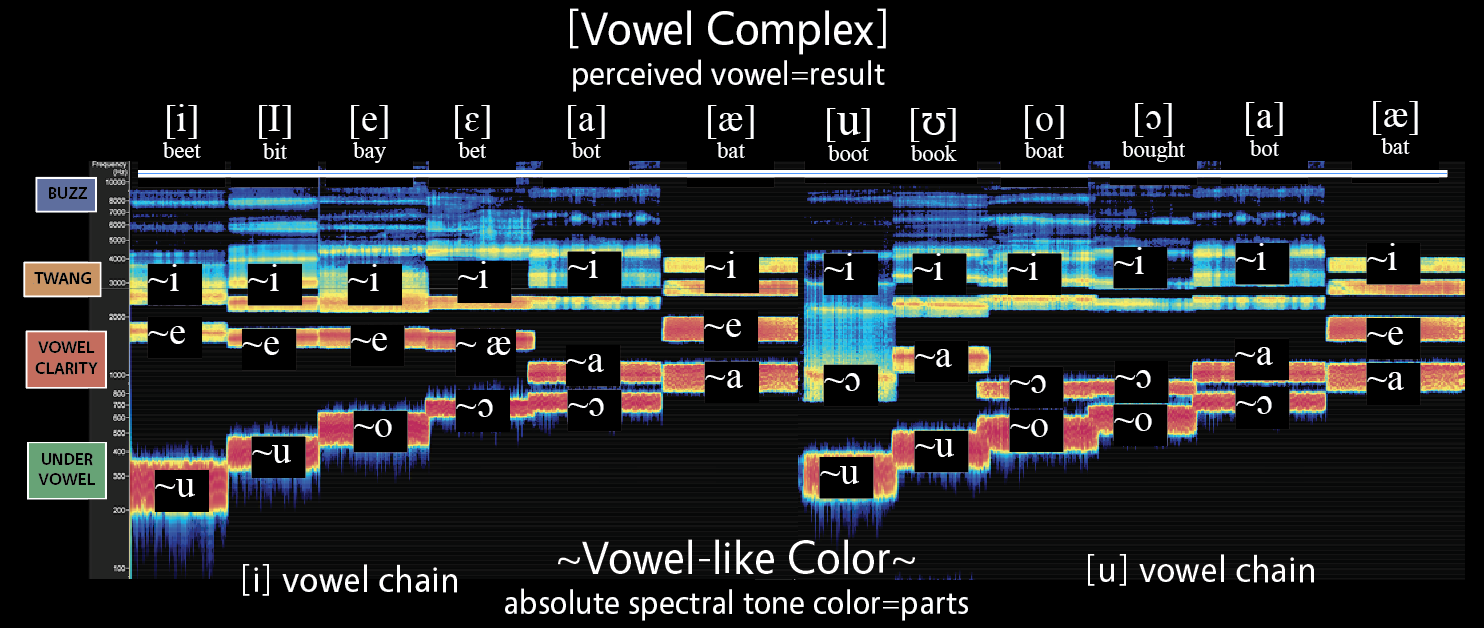
This image shows the [i] and [u] vowel chains through a spectrogram image of vocal fry filtered to show the energy boosts of the vocal tract. The vowel complex (the vowel that we perceive though it is made up of many vowel parts) is labeled along the top. The absolute spectral tone color individual vowel-like colors are labeled on the energy boosts. Note that these are the vowel-like colors that will be boosted in the sound, but they are not the only vowel-like colors present.
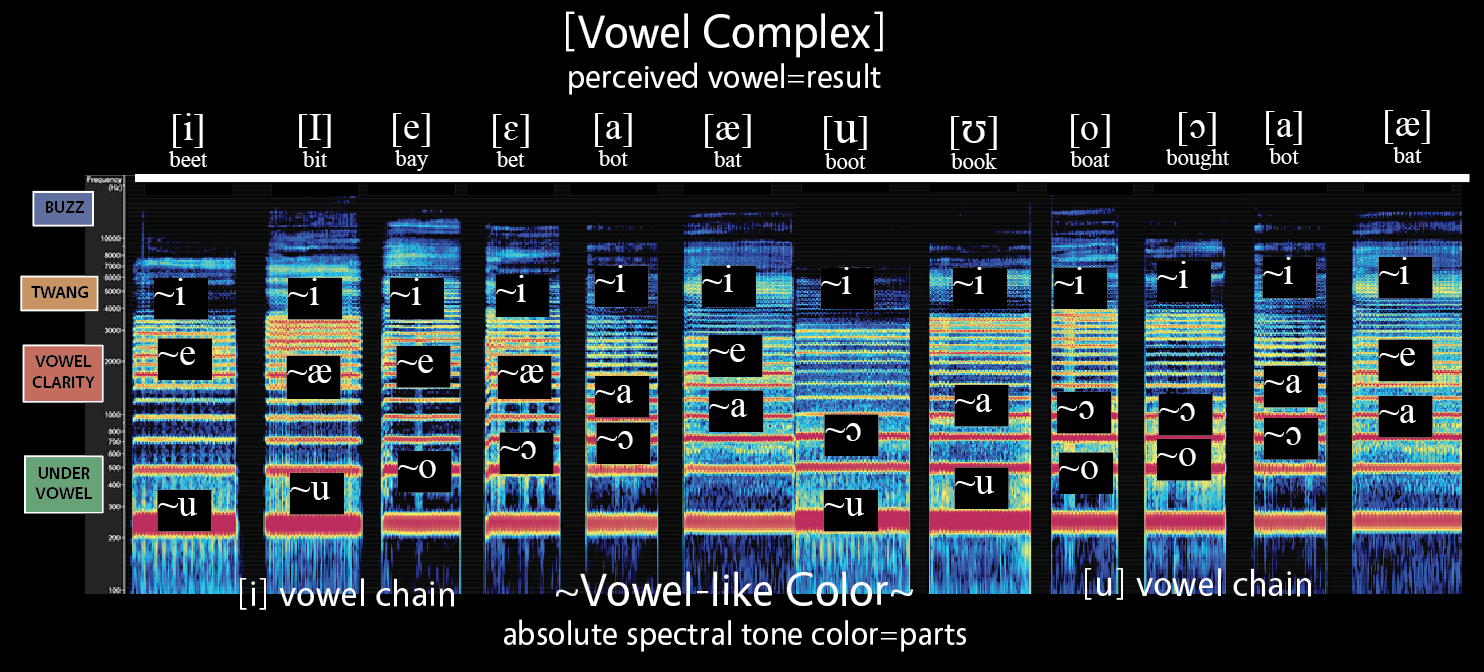
This image shows the same information, but with a spectrogram image of the [i] and [u] vowel chains sung on a C4 (256Hz) fundamental. Unlike the other, filtered, images in this article, this image shows the full array of harmonics present in each vowel complex. Notice how other vowel-like qualities are present, but not as prominent as the harmonics that are boosted by energy boosts (formants) from the vocal tract.
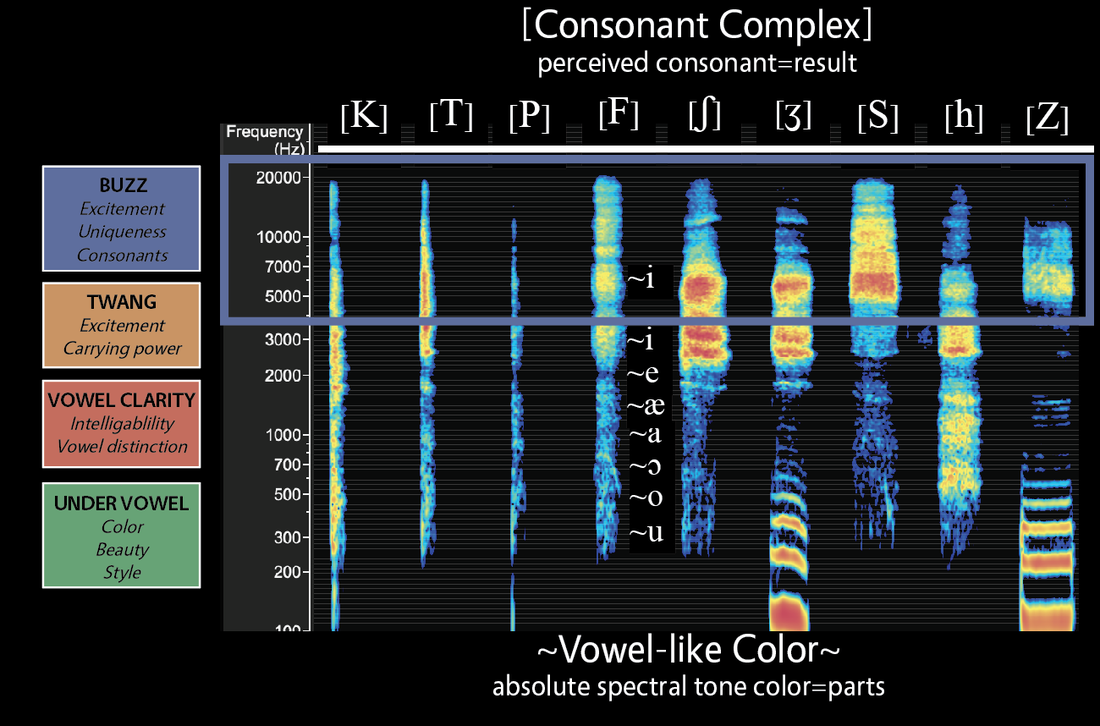
Consonants tend to be a-periodic, in that they are a combination of many sounds, or what might be thought of as "noise" (or a concentrated level of "buzziness"). Because there isn't one harmonic series represented, but, in fact, many harmonics in close proximity to one another (well beyond the "critical bandwidth"), consonants have a sonic quality different from vowels. Yet, they are still made up of the perceived vowel-like components that are traceable through absolute spectral tone color. If any narrow frequency band of any of these consonants were heard, it would sound vowel-like. Listen to the video "The Flute, The Trumpet, and the Lawn Mower" for a clear example of the sameness of sine waves regardless of their source. Howell describes this phenomenon in more detail saying:
"Essentially, sine tones have timbre. Psychoacoustics calls this phenomenon brightness. . .Sine tones appear to elicit not just relative timbral differences (a high tone is brighter compared to a low tone), but also absolute similarities. . .Two sine tones of the same frequency are identically bright. This is independent of other elements of timbre: attack, decay, release, or general spectro-temporal flux. . .The ASTC [absolute spectral tone color] of a harmonic remains constant so long as its frequency remains constant. This makes intuitive sense in visible color. The same color red can exist on a variety of objects, because the red percept is the result of sensory processing. So long as the same receptors in the eye are stimulated in the same way, it doesn’t matter the source. As the frequency of visible light increases or decreases, the perceived color changes. As a singer changes pitch, and every harmonic increases or decreases in frequency, each harmonic similarly changes ASTC in a predictable way. Conversely, as one changes vowels without changing pitch, any given harmonic only changes amplitude, not its individual ASTC. If one searches for a connection between the colors one sees and the colors one hears, ASTC is the appropriate analogy. A vowel is not a single color. A vowel is more like a painting made up of many individual colors" (pg 5).
Howell, Ian. "Necessary Roughness In Voice Pedagogy." VoicePrints: Journal of the New York Singing Teachers' Association. May-June 2017, pg 1-7.
"Essentially, sine tones have timbre. Psychoacoustics calls this phenomenon brightness. . .Sine tones appear to elicit not just relative timbral differences (a high tone is brighter compared to a low tone), but also absolute similarities. . .Two sine tones of the same frequency are identically bright. This is independent of other elements of timbre: attack, decay, release, or general spectro-temporal flux. . .The ASTC [absolute spectral tone color] of a harmonic remains constant so long as its frequency remains constant. This makes intuitive sense in visible color. The same color red can exist on a variety of objects, because the red percept is the result of sensory processing. So long as the same receptors in the eye are stimulated in the same way, it doesn’t matter the source. As the frequency of visible light increases or decreases, the perceived color changes. As a singer changes pitch, and every harmonic increases or decreases in frequency, each harmonic similarly changes ASTC in a predictable way. Conversely, as one changes vowels without changing pitch, any given harmonic only changes amplitude, not its individual ASTC. If one searches for a connection between the colors one sees and the colors one hears, ASTC is the appropriate analogy. A vowel is not a single color. A vowel is more like a painting made up of many individual colors" (pg 5).
Howell, Ian. "Necessary Roughness In Voice Pedagogy." VoicePrints: Journal of the New York Singing Teachers' Association. May-June 2017, pg 1-7.
|
|
This spectrogram recording shows the curious concept to human hearing known as absolute spectral tone color. The idea is that people hear vowel as pitch. Each frequency has a vowel-like quality, and when combined into complex combinations created by the vocal folds and vocal tract, people are able to communicate with seemingly endless variations. In this recording, the classic orchestral instruments of a flute, a trumpet, and a lawn mower all play a short excerpt. They are then all filtered for the same @1100Hz frequency range, a frequency band that sounds like "ah" to all humans. Note that it won't be the complex [a] that you are used to hearing in speech, but will be "ah"-like. Listen how each instrument, when filtered for the same frequency range, has the same vowel-like color, even though their more complex sounds are distinctly different. According to Howell, consistent perceptual qualities from individual vowel sounds "exist in every sound, regardless of its source; perhaps devoid of the additional sonic structures that differentiate a voice from a chainsaw, but present nonetheless. Imagine the low ‘oooooo oooooo’ of a foghorn or brilliant ‘eeeeeeeeeee’ of squealing car brakes. These onomatopoeic labels are both intuitive and inseparable from a human’s perception of the physical properties of each sound wave" (pg 17).
Howell, Ian. Parsing The Spectral Envelope. Doctoral Dissertation, New England Conservatory, 2016. |
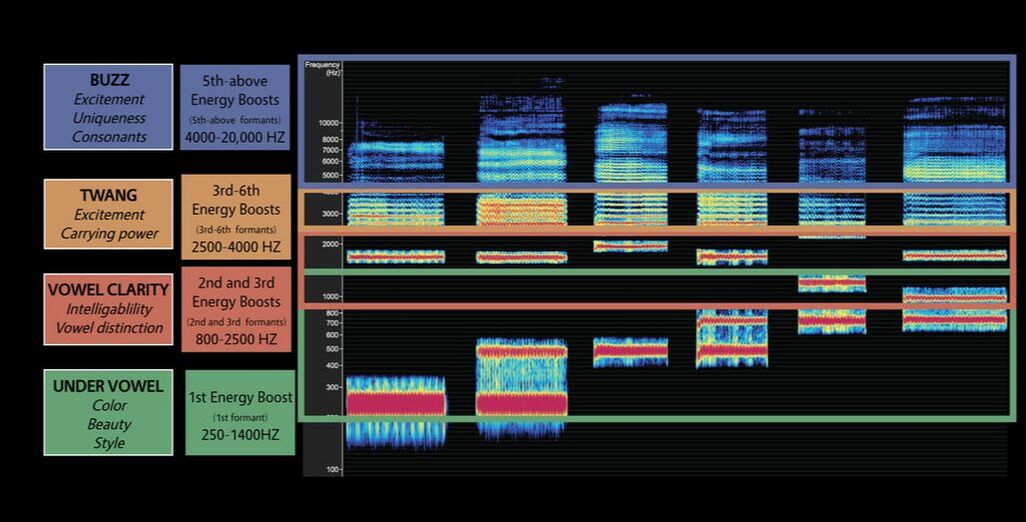
Inertance and Four Vocal Regions
Inertance is the mathematical concept that can be understood as acoustic support (read more on the Acoustic Strategies page). Each region’s energy boosts contribute to inertance. Therefore, when each area is more focused and aligned to the desired vocal outcome, acoustic support increases, making the overall experience of voicing more efficient, easier, and more aligned with sonic goals. By learning to hear the rainbow of options available within the wide range of resonant strategy options, the vocalist not only opens their ears and minds to a wealth of possibilities, they also increase their capacity toward strength, flexibility, efficiency, ease, and communication.
The VoiceScienceWorks ListenUP package is a two-week daily course specifically tailored to enhance each of the four vocal regions within each individual voice. For more information on how to experience your own ListenUP, send us an email.
Inertance is the mathematical concept that can be understood as acoustic support (read more on the Acoustic Strategies page). Each region’s energy boosts contribute to inertance. Therefore, when each area is more focused and aligned to the desired vocal outcome, acoustic support increases, making the overall experience of voicing more efficient, easier, and more aligned with sonic goals. By learning to hear the rainbow of options available within the wide range of resonant strategy options, the vocalist not only opens their ears and minds to a wealth of possibilities, they also increase their capacity toward strength, flexibility, efficiency, ease, and communication.
The VoiceScienceWorks ListenUP package is a two-week daily course specifically tailored to enhance each of the four vocal regions within each individual voice. For more information on how to experience your own ListenUP, send us an email.
In this video you can see how different singing styles boost different regions more or less. The results of these changes include emphasis on harmonics within different regions. The overall results of each is stability and vibrancy, though each one with differing combinations of the energy produced within the four regions. Watch each one, and pause as you go, taking a moment to see which of the regions is most active for each stylistic approach. The experience of noticing which regions are most active creates the opportunity to decipher which harmonics to filter in the filtered listening process.
Conclusion: Sound Can Change Your Life
Doctor, researcher, and filtered listening advocate Paul Madaule says the following about sound: "Like food and air, sound and all other sensory stimuli ‘feed’ the brain with the energy it needs to operate. High-frequency sounds (harmonics or overtones) in music and voice are more energizing than low-frequency sounds. As a result, openness and clarity in the upper range of the auditory spectrum is necessary for maintaining a high level of attention and focus while learning, practicing, and performing" (Listening Ear pg 39). Madaule has spent his life working with children who have learning disabilities and/or have been diagnosed with significant mental illnesses. He too was one of those children prior to encountering filtered listening through the help of Alfred Tomatis. Using filtered listening, he helps people regain mental and physical focus and live healthy lives. In his work, he has discovered the value of sound in ways that many vocalists have yet to appreciate. The technologies, research, and practical applications exist that make accessing the brain-nurturing capacity of sound approachable, even simple. As the brain is fed by sound, so is the voice guided by sound. Tomatis says:
“As we can see, in people who can hear, the ear is the principal force in this work. We sing with our ear, speak with our ear, stand upright and walk thanks to the ear. We perhaps even live thanks to our ear! This concept has two aspects:
Madaule, P. (2005). The Listening Ear. The American Music Teacher, 55(2), 38-39.
Tomatis, Alfred A. The Ear and the Voice. Scarecrow Press, Inc. Maryland, 1987/2001.
Doctor, researcher, and filtered listening advocate Paul Madaule says the following about sound: "Like food and air, sound and all other sensory stimuli ‘feed’ the brain with the energy it needs to operate. High-frequency sounds (harmonics or overtones) in music and voice are more energizing than low-frequency sounds. As a result, openness and clarity in the upper range of the auditory spectrum is necessary for maintaining a high level of attention and focus while learning, practicing, and performing" (Listening Ear pg 39). Madaule has spent his life working with children who have learning disabilities and/or have been diagnosed with significant mental illnesses. He too was one of those children prior to encountering filtered listening through the help of Alfred Tomatis. Using filtered listening, he helps people regain mental and physical focus and live healthy lives. In his work, he has discovered the value of sound in ways that many vocalists have yet to appreciate. The technologies, research, and practical applications exist that make accessing the brain-nurturing capacity of sound approachable, even simple. As the brain is fed by sound, so is the voice guided by sound. Tomatis says:
“As we can see, in people who can hear, the ear is the principal force in this work. We sing with our ear, speak with our ear, stand upright and walk thanks to the ear. We perhaps even live thanks to our ear! This concept has two aspects:
- A simple aspect in the sense that everyone thinks he knows what we mean by listening. In fact, the ability to listen is rare.
- A complex aspect that we have not yet come to terms with true listening. When we listen, we are utterly changed.” (Ear and Voice pg 25-26)
Madaule, P. (2005). The Listening Ear. The American Music Teacher, 55(2), 38-39.
Tomatis, Alfred A. The Ear and the Voice. Scarecrow Press, Inc. Maryland, 1987/2001.
"Remember: we sing with our ear."
~Alfred Tomatis
~Alfred Tomatis
