
Madde is a great tool for exploring harmonic/formant interaction. It’s free to download, and easy to learn to use. For download information visit our Software & Equipment page. If you'd like instruction in how we apply Madde and other software to understanding voice science concepts, join us at one of our online workshops throughout the year.
|
When discussing the vocal tract and it's influence on the entire vocal mechanism, we use the terms "acoustic strategies" or "resonance strategies". We prefer to focus on elements within the vocal mechanism that directly impact vocal color, stability, flexibility, and other desired vocal outcomes. Resonant strategies can be understood as separate influences on the whole vocal outcome, and are distinctly measurable. On our Filtered Listening and Vocal Regions page we explore the specific influence of the ear on the voice, and how to utilize harmonic information present in the vocal signature through listening to increase the influence of resonant strategies on the voice as a whole. The Vocal Strategies page defines resonant strategies as a concept and explores several approaches to accessing resonant strategies.
|
|
The voice is different than any other instrument. All other instruments have a resonator that can’t change shape, but the vocal tract can change shape radically, and small changes make big differences. When a violin plays, its resonator (the body of the instrument) accentuates the same basic harmonic output as the violin next to it. When a person sings, the same voice can accentuate a range of harmonic options even while singing the same note.
|
|
|
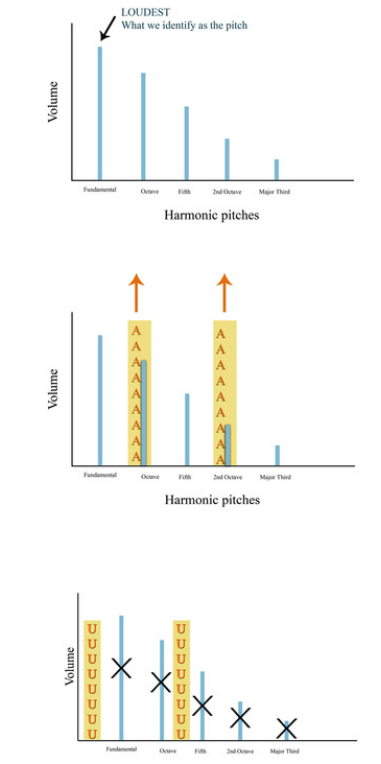
Basically, resonant strategies embody the alignment of energy boosts (formants) with one or more of the harmonics being produced by the vocal folds.
Visit our Harmonics vs. Formants page for more information on what harmonics and formants (energy boosts) are. Remember that the vocal folds produces a harmonic spectrum, and that the air in the vocal tract has pitch. When the frequency of one or more of the energy boosts (formants) aligns with one or more of the harmonics produced by the vocal folds, the sound is boosted in volume, stability, and energy. Resonant strategies relate specifically to how the vocal tract resonates the harmonics that are produced by the vocal folds. They include to the process of making specific acoustic choices in order to harness energy boosts (formants) to create formant/harmonic relationships that influence timbre, power, flexibility, etc. Resonant strategies are essential for determining how to create stability, modify vowels, and to sing in different styles. |
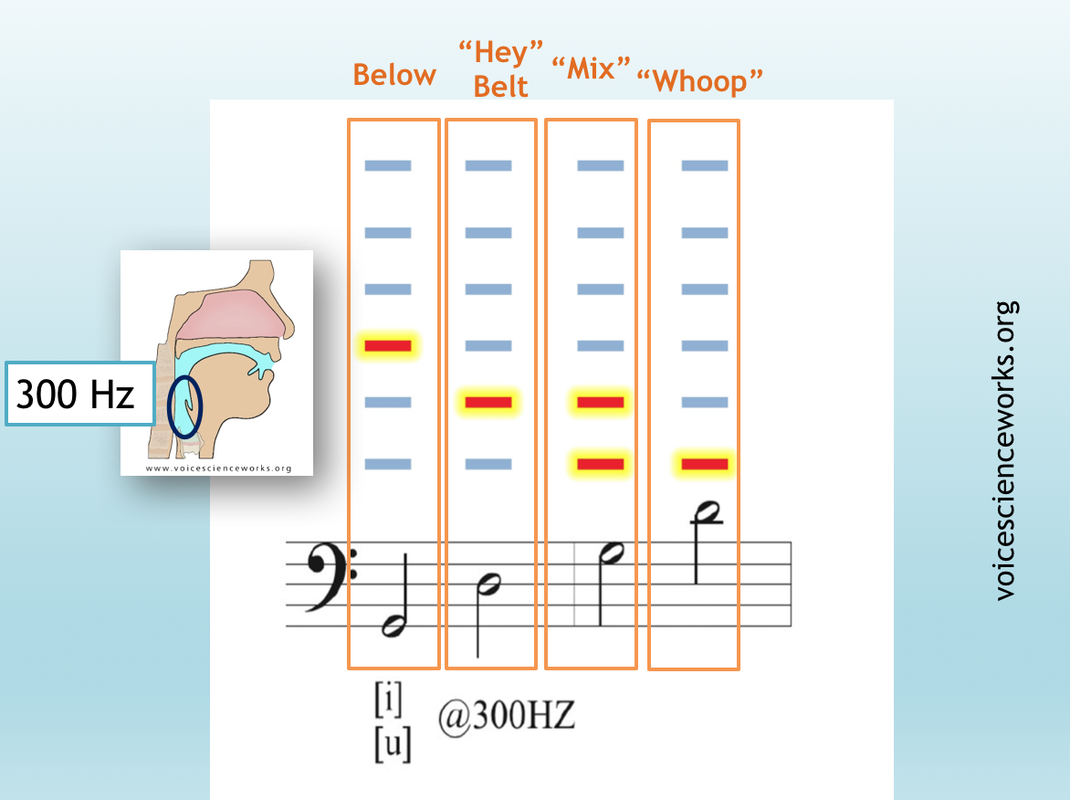
First Formant resonant strategies

|
The first and lowest energy boost (formant) can be understood as an energy peak that relates, roughly, to the pitch of the air that resides within the entire vocal tract. For simplicity sake, people often refer to the first energy boost (formant) as relating to the part of the vocal tract tube stretching from the vocal folds to the back of the tongue hump.
The first energy boost (formant) is always the lowest pitched resonance of the vocal tract. (note: the energy boost that is the first formant is actually influenced by the air in the entire vocal tract. If the mouth drops, for example, the first energy boost (formant) raises, even if the throat doesn't change. Traditional phonetics language makes a location distinction between the first (throat) and second (mouth) energy boosts that is convenient for a beginning understanding, but complicated in reality. There are two primal resonant strategies, called such because all people know how to use them instinctively. Kenneth Bozeman introduces these primal resonant strategies in his Practical Vocal Acoustics. We call them the “whoop” and the “hey” resonant strategies. Calling "hey" and whooping shape the vocal tract in ways that creates volume and stability. Try saying “hey” loudly, or “whoohoo!” to feel the effect. Because all people already have access to the sensations associated with these resonant strategies, training the primal resonant strategies first can open vocalists into more complex options by helping them begin to grasp the resonant strategy concept. Bozeman, Kenneth W. Practical Vocal Acoustics. Pendragon Press, Hilsdale, NY, 2013. Note that Bozeman uses the terms "whoop" and "yell". His use of the word "yell" is slightly different from our use of the word "hey", as "yell" refers distinctly to the coupling of the first energy boost with the second harmonic, and our use of "hey" refers to the coupling of the first energy boost with any harmonic other than the first. |
whoop
Act like your friend is across the street and you want to get their attention. Wave your hand vigorously as you call to them with a loud "You-hooooooo!" Notice how your voice sounds. Where do you feel it in your face/head? Many people say that they feel the "whoop" sensation in the back of their head, or further up in their face, near the forehead. These sensations can be subtle, there is no right place to feel them, and you might not feel anything at all. Noticing sensations provides a way widen attention, bringing tactile elements into play with your aural assessments.
The “whoop” sound that you created feels that way because your first energy boost (formant) coupled with your first harmonic. The kind of energy boost that this coupling created gave you a sensation higher up in your face/head, and caused your voice to sound warm, rich, floaty, smooth, or whatever other words you may have come up with for your experience. This resonant strategy encourages the vocal folds to assume a more ligament-dominant posture meaning that you use less laryngeal mass when whooping (see Inside The Larynx). For this reason, the vocal folds create a harmonic spectrum with less energy in the upper harmonics. People often employ the “whoop” resonant strategy for stylistic choices where they want more energy in the lower harmonics, or when they sing higher up in their range and need to avoid extra strain on the vocal fold muscles.
Note: the vocal folds don't have to respond to the "whoop" resonant strategy by moving into a ligament-dominant position, but they tend to need to be trained to use more muscle mass when whooping if that is desired.
You will notice below that in "whoop" timbre, fewer harmonics appear above the fundamental compared to the "hey" resonant strategy.
Read more about this: Bozeman, Ken. Practical Vocal Acoustics. Pendragon Press, 2013.
The “whoop” sound that you created feels that way because your first energy boost (formant) coupled with your first harmonic. The kind of energy boost that this coupling created gave you a sensation higher up in your face/head, and caused your voice to sound warm, rich, floaty, smooth, or whatever other words you may have come up with for your experience. This resonant strategy encourages the vocal folds to assume a more ligament-dominant posture meaning that you use less laryngeal mass when whooping (see Inside The Larynx). For this reason, the vocal folds create a harmonic spectrum with less energy in the upper harmonics. People often employ the “whoop” resonant strategy for stylistic choices where they want more energy in the lower harmonics, or when they sing higher up in their range and need to avoid extra strain on the vocal fold muscles.
Note: the vocal folds don't have to respond to the "whoop" resonant strategy by moving into a ligament-dominant position, but they tend to need to be trained to use more muscle mass when whooping if that is desired.
You will notice below that in "whoop" timbre, fewer harmonics appear above the fundamental compared to the "hey" resonant strategy.
Read more about this: Bozeman, Ken. Practical Vocal Acoustics. Pendragon Press, 2013.
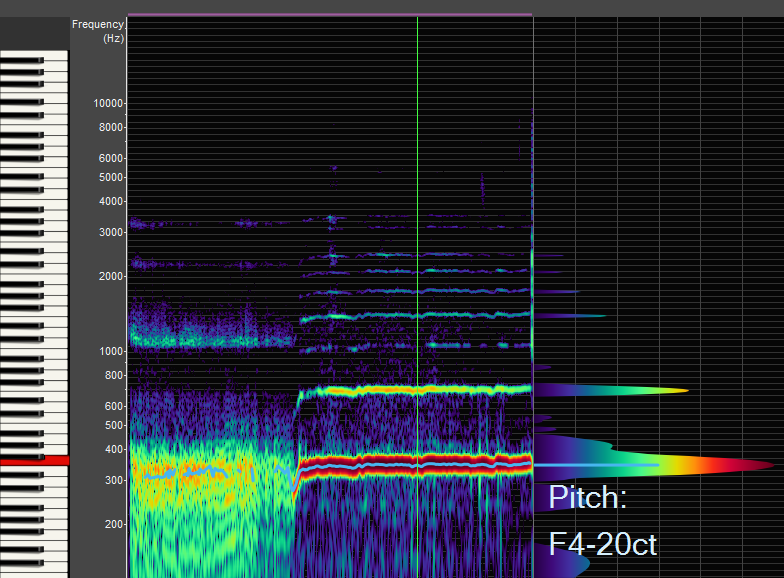
To read the spectral analyzer, notice the notes on the piano, the low notes are at the bottom of the screen. The harmonics are marked by colored lines that move left to right in time in the center of the image. The right 3rd of the image shows a single moment in time.
The yellow/green fuzzy area at the far left shows the first and second formant (created with vocal fry). The first formant here is around 350 HZ, the same as the first harmonic, demonstrating the “whoop” timbre.
This excerpt is sung by a male voice.
Hey
Act like your friend is across the street and you want to get their attention. Wave your hand vigorously as you call to them with a loud "Hey! Over Here!" Notice how your voice sounds. Where do you feel it in your face/head? Most people say that they feel the "hey" sensation in the front of their face, often around the upper teeth or nose area. These sensations can be subtle, there is no right place to feel them, and you might not feel anything at all. Noticing sensations provides a way widen attention, bringing tactile elements into play with your aural assessments.
The “hey” sound that you created feels that way because your first energy boost (formant) coupled with your second harmonic (or with the third or higher harmonic). The kind of boost that this coupling created gave you a sensation lower in your face/head, and caused your voice to sound large, powerful, brassy, bright, bold, or whatever other words you may have come up with for your experience. This resonant strategy often aligns with a muscle (TA) dominant vocal fold posture (see Inside The Larynx). People often employ the "hey" resonant strategy when they want more overall harmonic energy in their sound.
Note: the vocal folds don't have to respond to the "hey" resonant strategy by moving into a muscle dominant position, but they tend to need to be trained to use less muscle mass when using the "hey" strategy.
Read more about this: Bozeman, Ken. Practical Vocal Acoustics. Pendragon Press, 2013.
Note that Bozeman uses the term "yell" for this same resonant strategy. His use of the word "yell" is slightly different from our use of the word "hey", as "yell" refers distinctly to the coupling of the first energy boost with the second harmonic, and our use of "hey" refers to the coupling of the first energy boost with any harmonic other than the first.
The Upper "Hey": Describing the first energy boost (formant) interaction with upper harmonics
The lowest pitch that the first energy boost (formant) can create tends to be around 250-300 HZ, which would create an [u] or [i] vowel shape. When people sing lower in their range and/or utilize a vowel shape with higher first formant pitch (e.g. an [a] has an 800 HZ first energy boost (formant), their first energy boost (formant) interacts with higher harmonics, sometimes even the 7th harmonic or higher. Similar acoustic benefits exist when the first energy boost (formant) locks into any upper harmonic that lead us to describe first energy boost (formant ) coupling with upper harmonics as a "hey" resonant strategy as well. The result is nearly the same as that created by first energy boost (formant) coupling with the second harmonic. To speak in short-hand terms, we talk about an F1/H3 "hey" strategy to describe a "hey" in which the first energy boost (formant) couples with the third harmonic. By extension, an F1/H4 "hey" strategy would describe the first energy boost (formant) coupling with the fourth harmonic, and so on. This is an extension of Bozeman's initial description of "yell" as specific to the F1/H2 coupling.
You will notice below that in "hey" timbre, more harmonics appear above the fundamental compared to the "whoop" resonant strategy. This is largely because of the muscle-dominant vocal fold posture that increases energy in all harmonics.
The “hey” sound that you created feels that way because your first energy boost (formant) coupled with your second harmonic (or with the third or higher harmonic). The kind of boost that this coupling created gave you a sensation lower in your face/head, and caused your voice to sound large, powerful, brassy, bright, bold, or whatever other words you may have come up with for your experience. This resonant strategy often aligns with a muscle (TA) dominant vocal fold posture (see Inside The Larynx). People often employ the "hey" resonant strategy when they want more overall harmonic energy in their sound.
Note: the vocal folds don't have to respond to the "hey" resonant strategy by moving into a muscle dominant position, but they tend to need to be trained to use less muscle mass when using the "hey" strategy.
Read more about this: Bozeman, Ken. Practical Vocal Acoustics. Pendragon Press, 2013.
Note that Bozeman uses the term "yell" for this same resonant strategy. His use of the word "yell" is slightly different from our use of the word "hey", as "yell" refers distinctly to the coupling of the first energy boost with the second harmonic, and our use of "hey" refers to the coupling of the first energy boost with any harmonic other than the first.
The Upper "Hey": Describing the first energy boost (formant) interaction with upper harmonics
The lowest pitch that the first energy boost (formant) can create tends to be around 250-300 HZ, which would create an [u] or [i] vowel shape. When people sing lower in their range and/or utilize a vowel shape with higher first formant pitch (e.g. an [a] has an 800 HZ first energy boost (formant), their first energy boost (formant) interacts with higher harmonics, sometimes even the 7th harmonic or higher. Similar acoustic benefits exist when the first energy boost (formant) locks into any upper harmonic that lead us to describe first energy boost (formant ) coupling with upper harmonics as a "hey" resonant strategy as well. The result is nearly the same as that created by first energy boost (formant) coupling with the second harmonic. To speak in short-hand terms, we talk about an F1/H3 "hey" strategy to describe a "hey" in which the first energy boost (formant) couples with the third harmonic. By extension, an F1/H4 "hey" strategy would describe the first energy boost (formant) coupling with the fourth harmonic, and so on. This is an extension of Bozeman's initial description of "yell" as specific to the F1/H2 coupling.
You will notice below that in "hey" timbre, more harmonics appear above the fundamental compared to the "whoop" resonant strategy. This is largely because of the muscle-dominant vocal fold posture that increases energy in all harmonics.
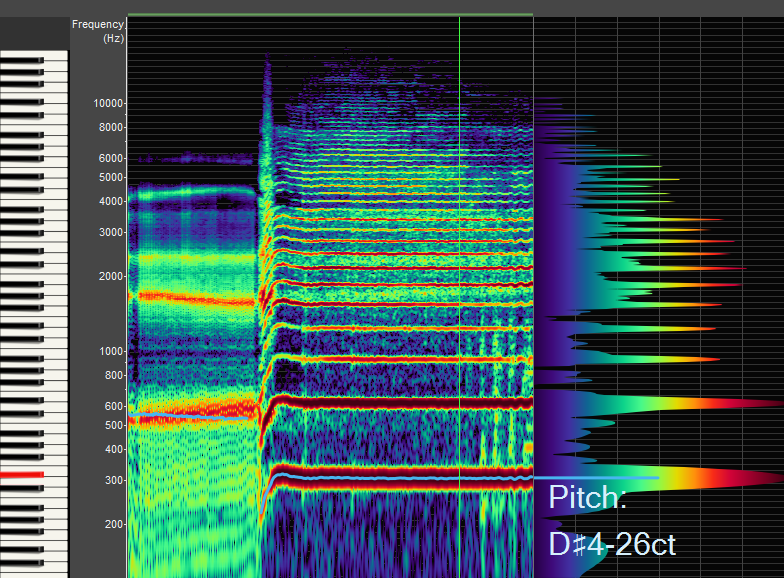
The first formant here is around 600 HZ, the same as the second harmonic, demonstrating the F1/H2 “hey” resonant strategy.
This excerpt is sung by a male voice.
Acoustic mix

Once singers have an understanding of the feeling of the “hey” and “whoop” resonant strategies, they can begin to expand into others. One of the more useful resonant strategies relies on allowing the first energy boost (formant) to sit in between two harmonics. This creates a different energy boost that resembles a combination of the "whoop" and "hey" timbral elements. This perceptual "mixture" of the two couples the warmth and richness of "whoop" timbre with the brassy vibrance of "hey" timbre. When the first energy boost (formant) sits between two harmonics, the vocal folds tend to respond by adjusting into a muscle mass dominant posture with less than the full muscle touching (see Inside The Larynx). Because the body enjoys the specific energy boost that occurs when the first energy boost (formant) directly couples with a harmonic, sustained positioning of the first energy boost (formant) between two harmonics can take some practice, and tends to be less intuitive. Training "acoustic mix," however, can lead to stability and tone colors that are desired in many styles. "Mix" is a term used across musical styles, and tends to be elusive. By starting with "acoustic mix", many of the other challenges encompassed within the broad term of "mix" can be aided.
In the same way that the "hey" resonant strategy can occur on harmonics 2 and above, the "acoustic mix" strategy can do the same. When the first energy boost (formant) sits between the second and third harmonics, for example, we say that the vocalist is using an F1/H2-H3 "acoustic mix" strategy.
Note: The term "mix" represents one of the more complicated concepts in vocal pedagogy. As noted on our Inside The Larynx page, the vocal folds are in constant adjustment between the stretchy (CT) and thickening (TA) muscles. These adjustments cause different amounts of the thickening (TA) muscle to be in contact at any given moment. Some have described three different muscle mass configurations that include 1) a ligament dominant posture with little to no thickening (TA) muscle in contact, 2) a muscle dominant posture with the full thickening muscle mass touching and 3) a muscle dominant posture with less than full thickening muscle mass touching. This last one has been called "mix". Because much of the vocalizing that people accomplish occurs in this more "middle" muscle mass configuration, we find it difficult to call all of the countless options of muscle mass configuration by the same, singular name of "mix." By contrast, the acoustic response to the first energy boost (formant) when it sits between two harmonics can easily be heard as a mixture of the "whoop" and "hey" timbres, and therefore, "mix" applies easily. Acoustically speaking, Ken Bozeman and others use the traditional language term "close timbre" to describe a similar acoustic occasion. See below for more on why we feel "Acoustic Mix" speaks with more clarity than "close timbre."
In the same way that the "hey" resonant strategy can occur on harmonics 2 and above, the "acoustic mix" strategy can do the same. When the first energy boost (formant) sits between the second and third harmonics, for example, we say that the vocalist is using an F1/H2-H3 "acoustic mix" strategy.
Note: The term "mix" represents one of the more complicated concepts in vocal pedagogy. As noted on our Inside The Larynx page, the vocal folds are in constant adjustment between the stretchy (CT) and thickening (TA) muscles. These adjustments cause different amounts of the thickening (TA) muscle to be in contact at any given moment. Some have described three different muscle mass configurations that include 1) a ligament dominant posture with little to no thickening (TA) muscle in contact, 2) a muscle dominant posture with the full thickening muscle mass touching and 3) a muscle dominant posture with less than full thickening muscle mass touching. This last one has been called "mix". Because much of the vocalizing that people accomplish occurs in this more "middle" muscle mass configuration, we find it difficult to call all of the countless options of muscle mass configuration by the same, singular name of "mix." By contrast, the acoustic response to the first energy boost (formant) when it sits between two harmonics can easily be heard as a mixture of the "whoop" and "hey" timbres, and therefore, "mix" applies easily. Acoustically speaking, Ken Bozeman and others use the traditional language term "close timbre" to describe a similar acoustic occasion. See below for more on why we feel "Acoustic Mix" speaks with more clarity than "close timbre."
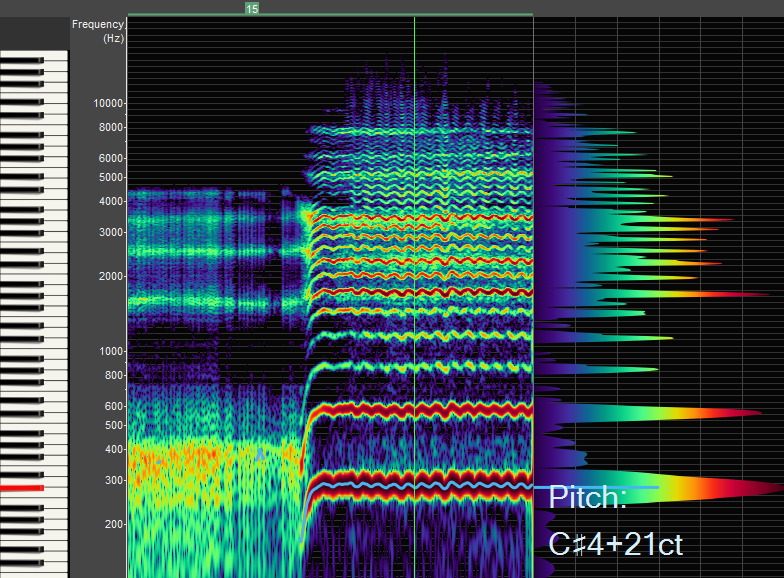
The first formant here is around 400 HZ, which sits between the first harmonic (300 Hz) and the second harmonic (600 HZ), demonstrating "mix" timbre, since both the first and second harmonics contribute to the timbral contribution of the first formant energy boost.
This excerpt is sung by a male voice.
The Three Birds Game
One of our favorite games that we've created for feeling the contrast between "hey", "acoustic mix", and "whoop" is The Three Birds Game. First, quack like a duck, like, a really annoying duck. Put that on a five note scale if you want. Then, quaw like a goose on the same scale and really be the goose. Describe the difference that you feel. Lastly, coo like a pigeon, yup, on the same scale, and, again, describe the differences you feel and hear. Although this isn't a fool-proof method for achieving these resonant strategies (that is, your body still has to agree), if you've allowed yourself to play the part of the three birds, then you've probably noticed a significant color shift in your sound with each bird. These color changes tend to align with "hey" for the duck, "acoustic mix" for the goose, and "whoop" for the pigeon. Try alternating them as you rise and fall through your range and see how your body responds.
Note: when being the duck, sometimes we can overly tighten our abdomen and throat muscles. This aligns with many people's experience with the "hey" resonant strategy. Try noticing if you can transfer your body's response to the pigeon over to the duck for greater ease across all birds.
One of our favorite games that we've created for feeling the contrast between "hey", "acoustic mix", and "whoop" is The Three Birds Game. First, quack like a duck, like, a really annoying duck. Put that on a five note scale if you want. Then, quaw like a goose on the same scale and really be the goose. Describe the difference that you feel. Lastly, coo like a pigeon, yup, on the same scale, and, again, describe the differences you feel and hear. Although this isn't a fool-proof method for achieving these resonant strategies (that is, your body still has to agree), if you've allowed yourself to play the part of the three birds, then you've probably noticed a significant color shift in your sound with each bird. These color changes tend to align with "hey" for the duck, "acoustic mix" for the goose, and "whoop" for the pigeon. Try alternating them as you rise and fall through your range and see how your body responds.
Note: when being the duck, sometimes we can overly tighten our abdomen and throat muscles. This aligns with many people's experience with the "hey" resonant strategy. Try noticing if you can transfer your body's response to the pigeon over to the duck for greater ease across all birds.
Vowel Modification
Vowel modification represents another type of resonant strategy. To begin to fully appreciate vowel modification, we must first separate the concept of vowel shape from the concept of vowel perception. Ian Howell in his Parsing the Spectral Envelope explains the basis of vowel perception in the concept he calls "absolute spectral tone color" (see below). The basic idea is that all individual frequencies sound slightly different to our ears, and that these differences are the basis of vowel perception. Some sound like [u], some like [a], some like [i], etc. Since we tend to sing and speak in tones that contain multiple frequencies, many of the sounds that we communicate with contain a mixture of many or all vowel-like sounds. Since many vowel sounds are often present, we have many vowel shape options available for communicating vowel sounds to people. We only need to boost enough of the vowel-like sounds for people to perceive our meaning within context (for example, consider the difference between a Bostonian, a Chicagoan, and a Birminghamer saying the word "Park").
Vowel shapes, therefore, reflect the vocal tract shapes that maximize the tones that, when combined, sound most like the vowel in question. We can focus on these shapes separately from the vowel perception.
Vowel shapes, therefore, reflect the vocal tract shapes that maximize the tones that, when combined, sound most like the vowel in question. We can focus on these shapes separately from the vowel perception.

Howell defines Absolute Spectral Tone Color as "any two or more simple sounds (e.g. a sine wave, single harmonic of a complex tone, or narrowly notch filtered band of noise) of identical frequency, regardless of their sources, will produce an identical tone color percept independent of other spectral fluctuations considered aspects of timbre. If these simple sounds are located within a complex sound, their inherent absolute spectral tone color is never lost or changed, only expressed or masked. These tone colors may be placed on a continuum, and bear a meaningful similarity to several vowels.” (Howell, "Parsing the Spectral Envelope," pages 29-20). Watch Ian explain it below.
The Vowel Chain
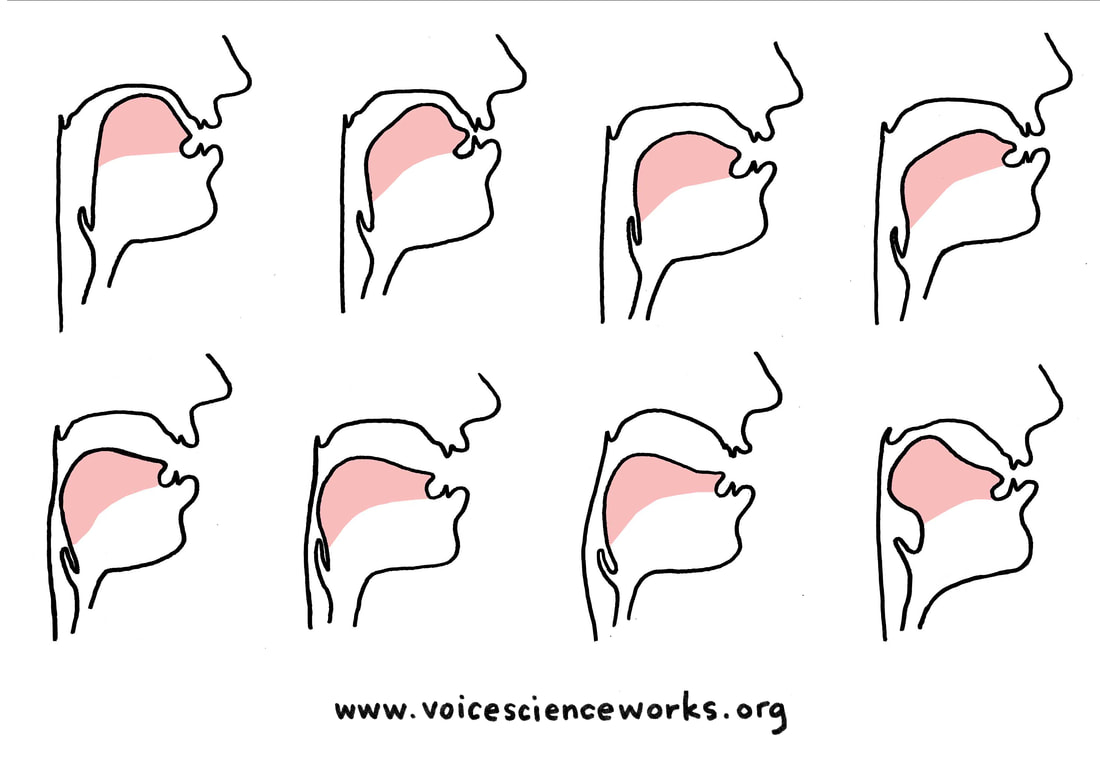
One basic acoustic reality follows that some vowel shapes boost lower harmonics while others boost higher harmonics. When focusing on the first energy boost (formant), the vowel shapes can be trained to maximize on "whoop", "hey", or "acoustic mix" timbre. This Vowel Chain exercise is organized such that the lower-pitched vowel shapes are located to the left, with the higher-pitched vowel shapes on the right. Vowel shapes that boost lower harmonics will feel more narrow, and those that boost higher harmonics will feel more wide. Listen for the harmonics in your sound to rise as you sing the exercise. This exercise works on any sung or spoken pitch because the first energy boost (formant) will always be the same for each vowel shape, so the lower pitched vowel shapes will always boost lower harmonics than the higher pitched ones.
One basic acoustic reality follows that some vowel shapes boost lower harmonics while others boost higher harmonics. When focusing on the first energy boost (formant), the vowel shapes can be trained to maximize on "whoop", "hey", or "acoustic mix" timbre. This Vowel Chain exercise is organized such that the lower-pitched vowel shapes are located to the left, with the higher-pitched vowel shapes on the right. Vowel shapes that boost lower harmonics will feel more narrow, and those that boost higher harmonics will feel more wide. Listen for the harmonics in your sound to rise as you sing the exercise. This exercise works on any sung or spoken pitch because the first energy boost (formant) will always be the same for each vowel shape, so the lower pitched vowel shapes will always boost lower harmonics than the higher pitched ones.

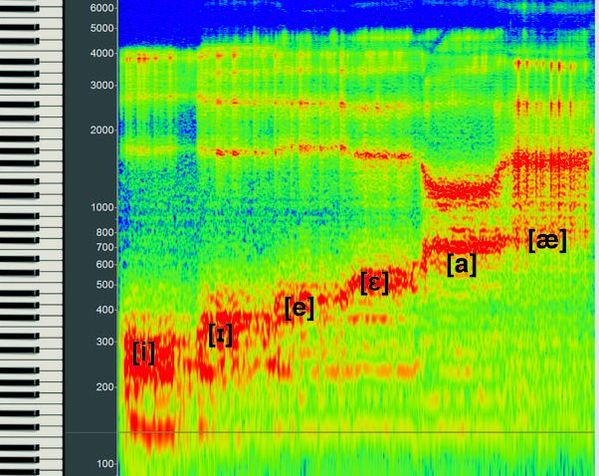
This spectrogram shows the first energy boost (formant) values for the [i] Vowel Chain. Note that energy boost (formant) values can change slightly per person because everyone's vocal tract shape is slightly different.
|
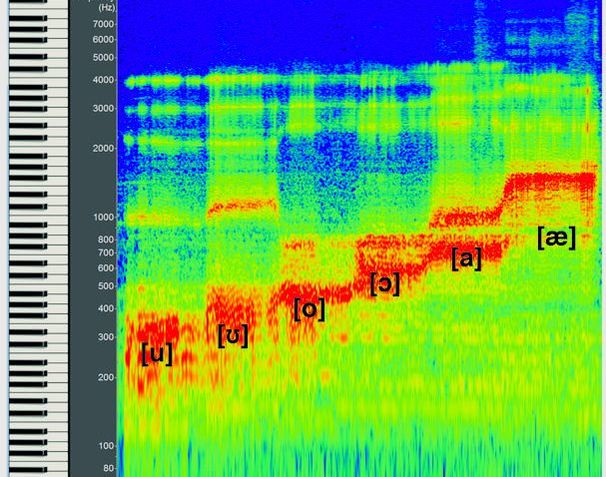
This spectrogram shows the first energy boost (formant) values for the [u] Vowel Chain. Note that energy boost (formant) values can change slightly per person because everyone's vocal tract shape is slightly different.
|
Stable Vowel Shape
A second basic acoustic reality follows that if a vowel shape remains stable, lower pitches sung with that shape will feel “wider,” while higher pitches sung with that shape will feel more “narrow.” For example, a G2 sung with an [i] vowel shape (whose first energy boost (formant) is around 300HZ) will boost the third harmonic. If you maintain that vowel shape and sing D3, you'll boost the second harmonic creating "hey" timbre, sing G3 and you'll boost the first and second harmonic creating "acoustic mix" timbre, and sing D4 and you'll boost the first harmonic creating "whoop" timbre. The G2 sung with an [i] vowel shape will feel "wider" than the D3 sung with the [i] vowel shape.
By contrast, a vowel shape with a much higher first energy boost (formant) like the [a] vowel shape (whose first energy boost is around 800HZ) sung on the same G2 will boost the 8th harmonic, feeling much "wider" than the same note sung on the lower pitched [i] vowel shape.
A second basic acoustic reality follows that if a vowel shape remains stable, lower pitches sung with that shape will feel “wider,” while higher pitches sung with that shape will feel more “narrow.” For example, a G2 sung with an [i] vowel shape (whose first energy boost (formant) is around 300HZ) will boost the third harmonic. If you maintain that vowel shape and sing D3, you'll boost the second harmonic creating "hey" timbre, sing G3 and you'll boost the first and second harmonic creating "acoustic mix" timbre, and sing D4 and you'll boost the first harmonic creating "whoop" timbre. The G2 sung with an [i] vowel shape will feel "wider" than the D3 sung with the [i] vowel shape.
By contrast, a vowel shape with a much higher first energy boost (formant) like the [a] vowel shape (whose first energy boost is around 800HZ) sung on the same G2 will boost the 8th harmonic, feeling much "wider" than the same note sung on the lower pitched [i] vowel shape.
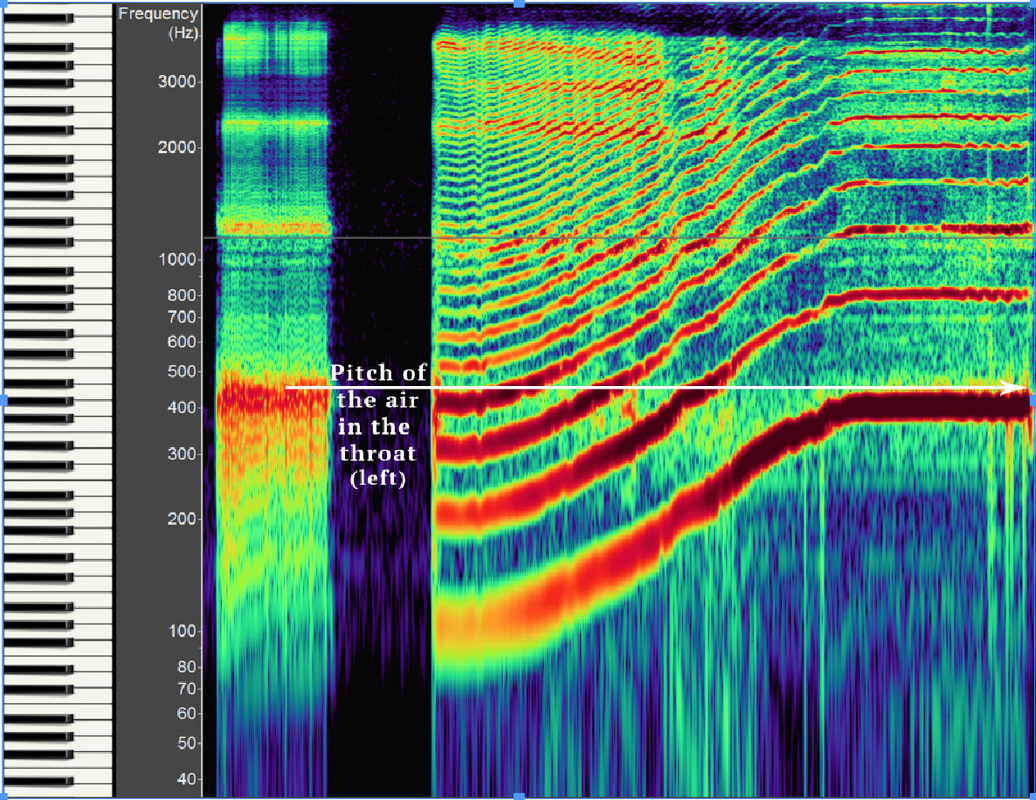
A male singer singing a 2-octave glide with the same vowel shape. Notice the first energy boost (formant) on the left @400HZ shown through vocal fry. As the singer glides across two octaves, note how the highlighted harmonic changes, telling us that the first energy boost (formant) remains stable. At the lower sung pitch (to the left), the first energy boost (formant) boosts a higher harmonic, and therefore feels "wider" than at the higher sung pitch (to the right), which will feel and sound more "narrow".
|
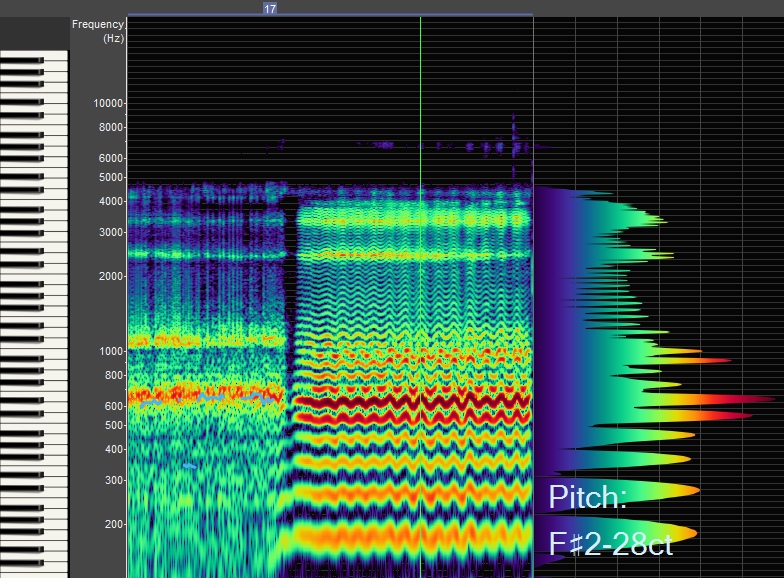
The first energy boost (formant) in this image sits around 600 Hz. Notice how the first energy boost (formant) primarily couples with the sixth harmonic. We describe this as a F1/H6 "hey" resonant strategy.
This excerpt is sung by a male voice.
|
In conclusion, the first energy boost (formant) plays a major role in the overall timbre of the sounds that we can create with our voices. Three of those timbres, "whoop", "hey", and "acoustic mix" play important roles in creating stylistic variation, and with informing laryngeal stability.
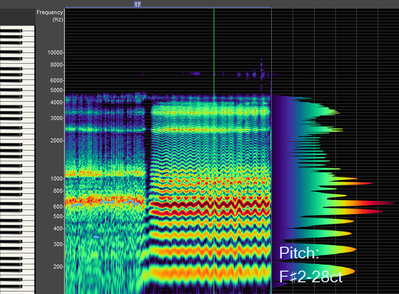 If you vocal fry into a voice analyzer, you can see the formants appear. On the left of this image, the first formant is orange, the second formant is yellow, and the third, fourth, fifth, and sixth formants are represented by light green lines between 2000-4000HZ. Note how the formants boost the harmonics they are parallel to.
If you vocal fry into a voice analyzer, you can see the formants appear. On the left of this image, the first formant is orange, the second formant is yellow, and the third, fourth, fifth, and sixth formants are represented by light green lines between 2000-4000HZ. Note how the formants boost the harmonics they are parallel to.
The Vowel Clarity Region and The Twang Region
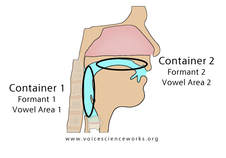
Since the vocal tract is comprised of many different containers of air, there are many opportunities to adjust the vocal tract shape to create energy boost or dampen energy. The Vowel Clarity Region is occupied primarily by the second energy boost (formant), but can also be influenced by the third energy boost. The second energy boost (formant) primarily influenced by the air in the mouth, and is therefore easy to imagine and feel the results of. Bozeman talks about these sensations at length. The second energy boost (formant) is the second largest and influential energy boost, and is responsible for the majority of the vowel perception that we experience. Refer to Ian Howell's diagram above that shows the absolute spectral tone color of different frequencies. The second energy boost (formant) boosts energy in the frequency range from around 800HZ to around 2500HZ , the range that includes all vowel-like timbres except for the [u] and [o]. See our Filtered Listening and Vocal Regions page for more information about accessing these two regions.
The Twang Region refers to a frequency band between 2500-4000Hz. This region is unique physiologically, because the auditory canal vibrates at this same frequency band, giving these frequencies extra energy when they reach the auditory cortex. The 3rd-6th energy boosts (formants) can all boost energy in this frequency band, and energy boosts (formants) 4 and 5 almost always boost energy in this frequency band. These energy boosts (formants) are directly influenced by the tiny epilarynx tube that resides just above the vocal folds. Like the vocal folds, people don't have direct tactile association with the epilarynx tube, but can find ways to describe their experience based on the results that occur from epilaryngeal focusing. When energy increases in the Twang Region, inertance increases significantly (see below) creating stability in the vocal folds. This makes the tiny epilarynx tube essential, since by increasing inertance/stability, the vocal folds vibrate more easily, making vocal goals more accessible.
Formants are somewhat complicated scientific concepts that refer to a physical/anatomical location and posture, the air associated within that location, the perceptual result of that air, and the energy created as sound propagates within the vocal tract and receives boosts as harmonics align with them. By combining of these concepts, we can surmise that formants are energy boosts that result from small pockets of air in the vocal tract creating a perceptual difference to sound emitting from the voice. These pockets of air change in pitch and energy every time the vocal tract changes shape. Shape changes occur each time a person changes vowel or consonant, swallow, yawn, etc., so, quite often.
The frequencies associated with the lowest seven energy boosts can relatively be described as:
The first energy boost (formant) can range from around 250Hz-1400Hz, but more frequently people top out around 1000Hz.
The second energy boost (formant) can range from 800-2500Hz.
The third energy boost (formant) can range from as low as 1400 Hz (like in an [ɹ] sound), and as high as 2500Hz.
The fourth energy boost (formant) can range from 2500-3500HZ.
The fifth energy boost (formant) can range from 3000-4000Hz.
The sixth energy boost (formant) can range from 3500-4500Hz.
The seventh energy boost (formant) can range from 4500-5500Hz and so on.
All of these energy boosts can migrate as much as 1000Hz, which is rather significant. This means that resonant strategies vary widely, and that vocalists have significant opportunities to create new sounds. See our Filtered Listening and Vocal Regions page for more information.
Energy Boost (Formant) Clustering and Spreading
Energy boosts (formants) have the capacity to cluster together or spread apart from one another. The easiest example of this is the difference between the first two energy boosts (formants) contrasted on an [i] vowel shape and an [a] vowel shape. On an [i] vowel shape the first energy boost (formant) sits around 250 HZ and the second energy boost (formant) sits around 2200 HZ, making them quite spread apart, and all of the energy between them dampened. On an [a] vowel shape, the first energy boost (formant) sits around 800 HZ and the second energy boost (formant ) sits around 1200 HZ. Their relative closeness makes them couple or clustere. All of the harmonics within the range of these two energy boosts (formants) get boosted because of their close proximity.
The second and third energy boosts cluster in certain phonemes like an [ɹ] sound), which is essential for overtone singing (see Extended Techniques for more), and is a technique used in many different styles to help create inertance.
Energy boosts (formants) 3-6 (and above) are often clustered or spread as well. Certain vocalization styles (e.g. pop, jazz, and musical theater) often emphasize the spreading of these upper energy boosts (formants), where others (e.g. opera, legit musical theater, choral singing, and Balkan singing) emphasize clustering. Combinations of the two exist as well. Metal singing, for example, often utilizes a clustering of the 2nd and 3rd energy boosts, a spreading of the 4th-6th energy boosts, and a subsequent clustering of the 7th and 8th energy boosts. When spread, the upper energy boosts (formants) boost more harmonics overall. When clustered, the upper energy boosts (formants) focus energy into selected harmonics. These differences can create significant timbral differences.
Since the vocal tract is comprised of many different containers of air, there are many opportunities to adjust the vocal tract shape to create energy boost or dampen energy. The Vowel Clarity Region is occupied primarily by the second energy boost (formant), but can also be influenced by the third energy boost. The second energy boost (formant) primarily influenced by the air in the mouth, and is therefore easy to imagine and feel the results of. Bozeman talks about these sensations at length. The second energy boost (formant) is the second largest and influential energy boost, and is responsible for the majority of the vowel perception that we experience. Refer to Ian Howell's diagram above that shows the absolute spectral tone color of different frequencies. The second energy boost (formant) boosts energy in the frequency range from around 800HZ to around 2500HZ , the range that includes all vowel-like timbres except for the [u] and [o]. See our Filtered Listening and Vocal Regions page for more information about accessing these two regions.
The Twang Region refers to a frequency band between 2500-4000Hz. This region is unique physiologically, because the auditory canal vibrates at this same frequency band, giving these frequencies extra energy when they reach the auditory cortex. The 3rd-6th energy boosts (formants) can all boost energy in this frequency band, and energy boosts (formants) 4 and 5 almost always boost energy in this frequency band. These energy boosts (formants) are directly influenced by the tiny epilarynx tube that resides just above the vocal folds. Like the vocal folds, people don't have direct tactile association with the epilarynx tube, but can find ways to describe their experience based on the results that occur from epilaryngeal focusing. When energy increases in the Twang Region, inertance increases significantly (see below) creating stability in the vocal folds. This makes the tiny epilarynx tube essential, since by increasing inertance/stability, the vocal folds vibrate more easily, making vocal goals more accessible.
Formants are somewhat complicated scientific concepts that refer to a physical/anatomical location and posture, the air associated within that location, the perceptual result of that air, and the energy created as sound propagates within the vocal tract and receives boosts as harmonics align with them. By combining of these concepts, we can surmise that formants are energy boosts that result from small pockets of air in the vocal tract creating a perceptual difference to sound emitting from the voice. These pockets of air change in pitch and energy every time the vocal tract changes shape. Shape changes occur each time a person changes vowel or consonant, swallow, yawn, etc., so, quite often.
The frequencies associated with the lowest seven energy boosts can relatively be described as:
The first energy boost (formant) can range from around 250Hz-1400Hz, but more frequently people top out around 1000Hz.
The second energy boost (formant) can range from 800-2500Hz.
The third energy boost (formant) can range from as low as 1400 Hz (like in an [ɹ] sound), and as high as 2500Hz.
The fourth energy boost (formant) can range from 2500-3500HZ.
The fifth energy boost (formant) can range from 3000-4000Hz.
The sixth energy boost (formant) can range from 3500-4500Hz.
The seventh energy boost (formant) can range from 4500-5500Hz and so on.
All of these energy boosts can migrate as much as 1000Hz, which is rather significant. This means that resonant strategies vary widely, and that vocalists have significant opportunities to create new sounds. See our Filtered Listening and Vocal Regions page for more information.
Energy Boost (Formant) Clustering and Spreading
Energy boosts (formants) have the capacity to cluster together or spread apart from one another. The easiest example of this is the difference between the first two energy boosts (formants) contrasted on an [i] vowel shape and an [a] vowel shape. On an [i] vowel shape the first energy boost (formant) sits around 250 HZ and the second energy boost (formant) sits around 2200 HZ, making them quite spread apart, and all of the energy between them dampened. On an [a] vowel shape, the first energy boost (formant) sits around 800 HZ and the second energy boost (formant ) sits around 1200 HZ. Their relative closeness makes them couple or clustere. All of the harmonics within the range of these two energy boosts (formants) get boosted because of their close proximity.
The second and third energy boosts cluster in certain phonemes like an [ɹ] sound), which is essential for overtone singing (see Extended Techniques for more), and is a technique used in many different styles to help create inertance.
Energy boosts (formants) 3-6 (and above) are often clustered or spread as well. Certain vocalization styles (e.g. pop, jazz, and musical theater) often emphasize the spreading of these upper energy boosts (formants), where others (e.g. opera, legit musical theater, choral singing, and Balkan singing) emphasize clustering. Combinations of the two exist as well. Metal singing, for example, often utilizes a clustering of the 2nd and 3rd energy boosts, a spreading of the 4th-6th energy boosts, and a subsequent clustering of the 7th and 8th energy boosts. When spread, the upper energy boosts (formants) boost more harmonics overall. When clustered, the upper energy boosts (formants) focus energy into selected harmonics. These differences can create significant timbral differences.
|
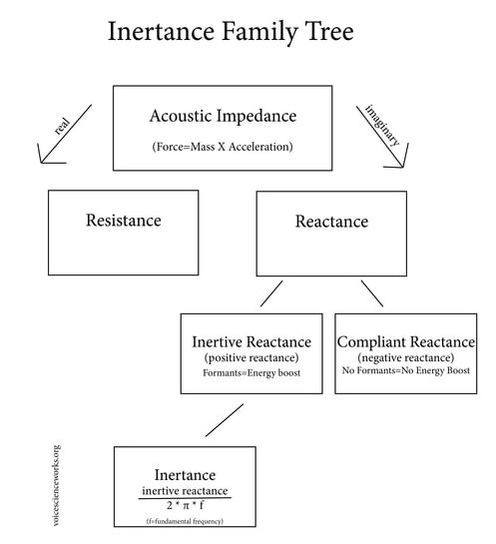
Inertance is one of the more difficult acoustic concepts to understand, so this is just a teaser. When we start to build a working understanding of inertance, it has a way of guiding major vocal decisions. Think of inertance like balance. Inertance is the ultimate result of the balance between breath pressure from below the vocal folds and acoustic back pressure from above the vocal folds. Acoustic back pressure occurs when the different energy boosts of the vocal tract align with harmonics such that energy returns to the vocal folds. When these pressures are in balance, the vocal folds can operate most efficiently. Technically speaking, inertance is part of the whole concept known as acoustic impedance, but, for the sake of ease, we'll just talk about the result of inertance as synonymous with acoustic impedance.
|
Think about it this way: If breath pressure from below is of a greater or lesser energy than acoustic back pressure from above, then the vocal folds have to work extra hard to stay in contact. This will have an audible impact on the sound, and on how it feels to make sound.
Importantly, since the muscles that most influence breath pressure are larger, and less capable of fine tuning than the acoustic resonator, and since we respond most quickly to acoustic adjustments through the use of our ears, inertive changes can occur most easily through changes in the vocal tract, or, acoustic strategies.
A common example of an acoustic strategy adjustments that increase inertance can be found by engaging the tongue root, an action that results in the [ɹ] sound and is sometimes referred to as "pulling the tongue back." Lots of vocalists from all professions and styles engage their tongue root in order to increase inertance, thereby helping to balance the energy from below and above the vocal folds by narrowing the epilarynx tube (see Twang Region and Kerri Obert's work). While they increase their chances for balance, they also color their sound significantly by increasing energy in the 1400-2000HZ range, leading to a distinctive [ɹ] color in their vocal signature. Another way to increase inertance is by narrowing the epilarynx tube through pharyngeal wall narrowing rresulting in what some call "twang" or "the singer's formant cluster." This adjustment creates a squeal/ring/ping/whine sound that is an evident aspect of the overall sound. All of the resonant strategies above will yield increased inertance. SOVT exercises also increase inertance, training the body to make acoustic strategy choices that help balance the mechanism.
For more on this, see Ingo R. Titze and Katherine Verdolini Abbott, Vocology: The Science and Practice of Voice Habilitation (Iowa City: National Center for Voice and Speech, 2012).
Importantly, since the muscles that most influence breath pressure are larger, and less capable of fine tuning than the acoustic resonator, and since we respond most quickly to acoustic adjustments through the use of our ears, inertive changes can occur most easily through changes in the vocal tract, or, acoustic strategies.
A common example of an acoustic strategy adjustments that increase inertance can be found by engaging the tongue root, an action that results in the [ɹ] sound and is sometimes referred to as "pulling the tongue back." Lots of vocalists from all professions and styles engage their tongue root in order to increase inertance, thereby helping to balance the energy from below and above the vocal folds by narrowing the epilarynx tube (see Twang Region and Kerri Obert's work). While they increase their chances for balance, they also color their sound significantly by increasing energy in the 1400-2000HZ range, leading to a distinctive [ɹ] color in their vocal signature. Another way to increase inertance is by narrowing the epilarynx tube through pharyngeal wall narrowing rresulting in what some call "twang" or "the singer's formant cluster." This adjustment creates a squeal/ring/ping/whine sound that is an evident aspect of the overall sound. All of the resonant strategies above will yield increased inertance. SOVT exercises also increase inertance, training the body to make acoustic strategy choices that help balance the mechanism.
For more on this, see Ingo R. Titze and Katherine Verdolini Abbott, Vocology: The Science and Practice of Voice Habilitation (Iowa City: National Center for Voice and Speech, 2012).
|
Traditional Resonant Strategy Language Challenges: “close” and “open”
In traditional Italian instruction, the terms “voce aperta” (open voice) and “voce chiusa” (closed voice) came into use to describe “the kind of voice we don’t want to have” (open) and “the kind we want to have” (closed), according to Matt Hoch’s “A Dictionary For The Modern Singer.” In contemporary pedagogy and phonetics, these ideas have been given new life, with each describing specific mechanical and acoustic experiences that lead to specific vocalizations. Importantly, the word “closed” has been changed to “close” in this new iteration. Hoch, Matthew. A Dictionary For The Modern Singer. Rowman & Littlefield, Lanham, MD, 2014. |
The Pink Trombone website provides a fun way to explore some vocal tract shape changes. Click the image to explore the site.
|
Challenge 1: IPA and the physical definition and prescribed adjustments process
The International Phonetic Alphabet defines vowels and consonants by the physical structural adjustments of the vocal tract. The terms “open”, “mid”, and “close” refer to three general tongue positions with “open” being as far from the roof of the mouth as possible, “close” being as close to the roof of the mouth without touching it, and “mid” being in between. A quick review of the IPA chart reveals that copious gradations of these three general areas exist in order to make sense of all of the vowel sounds available in human languages.
The International Phonetic Alphabet defines vowels and consonants by the physical structural adjustments of the vocal tract. The terms “open”, “mid”, and “close” refer to three general tongue positions with “open” being as far from the roof of the mouth as possible, “close” being as close to the roof of the mouth without touching it, and “mid” being in between. A quick review of the IPA chart reveals that copious gradations of these three general areas exist in order to make sense of all of the vowel sounds available in human languages.

"IPA Chart, http://www.internationalphoneticassociation.org/content/ipa-chart, available under a Creative Commons Attribution-Sharealike 3.0 Unported License. Copyright © 2015 International Phonetic Association."
|
This system creates ample opportunity to differentiate the many variations that our vocal tract can achieve, however, it causes challenges to voice users attempting to reproduce the sounds while performing. Tiny adjustments to the tongue or lips are simply too hard to track and manage while trying to phonate in performance. Although we feel movement in the mouth from one vowel to the next, voice users don’t feel the specificity of tongue movement necessary to make meaningful pedagogical practice out of mechanical motion of vocal tract muscles. Further, voice users tend to map many of the sensations that they feel opposite to what actually occurs (see Ken Bozeman “Kinesthetic Voice Pedagogy”, chapter 2).
For fun, try instructing someone to create a vowel sound in a language unfamiliar to them with only the instructions “no, more close” “no, more mid” or “no, more open” and nothing else (especially no voiced sound examples) and see how well it goes. By contrast, using the ear to guide the voice eliminates these challenging language connundrums. |
Challenge 2: Acoustic feedback paradigms
Ken Bozeman and others have led the charge in the important work of applying contemporary voice research to traditional language. In doing so, he and others have begun to codify the new iterations of open and close. The new terms, however, have a double meaning that can overlap and lead to confusion. The first meaning is similar to that of the IPA usage, with close vowels being those that have fronted, high tongue positions and open vowels being those with back, low tongue positions.
The second meaning relates to acoustic strategies and is used with the word “timbre”. A close timbre relies on a vowel that, for a given sung pitch, locates the first energy boost (formant) frequency between the first and second harmonic. An open timbre relies on a vowel that, for a given sung pitch, locates the first energy boost (formant) frequency higher than an octave above the sung pitch. Therefore, according to these definitions, a singer can sing a close vowel and create an open timbre, depending on the pitch they sing. Although this exploration of acoustic strategies stands as an important chapter in vocology, the apparent confusion that can ensue because of the double meaning of the terminology limits its effectiveness.
Ken Bozeman and others have led the charge in the important work of applying contemporary voice research to traditional language. In doing so, he and others have begun to codify the new iterations of open and close. The new terms, however, have a double meaning that can overlap and lead to confusion. The first meaning is similar to that of the IPA usage, with close vowels being those that have fronted, high tongue positions and open vowels being those with back, low tongue positions.
The second meaning relates to acoustic strategies and is used with the word “timbre”. A close timbre relies on a vowel that, for a given sung pitch, locates the first energy boost (formant) frequency between the first and second harmonic. An open timbre relies on a vowel that, for a given sung pitch, locates the first energy boost (formant) frequency higher than an octave above the sung pitch. Therefore, according to these definitions, a singer can sing a close vowel and create an open timbre, depending on the pitch they sing. Although this exploration of acoustic strategies stands as an important chapter in vocology, the apparent confusion that can ensue because of the double meaning of the terminology limits its effectiveness.
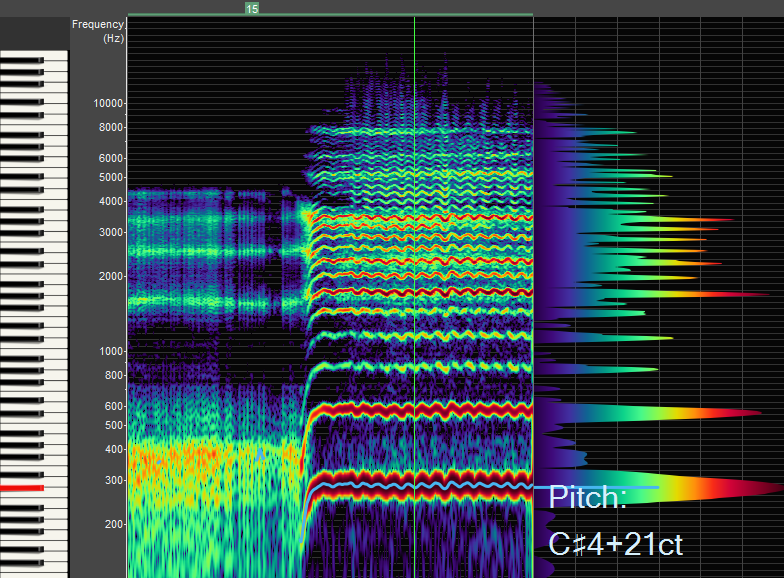
F1 sits between H1 and H2, the definition of "close timbre."
|
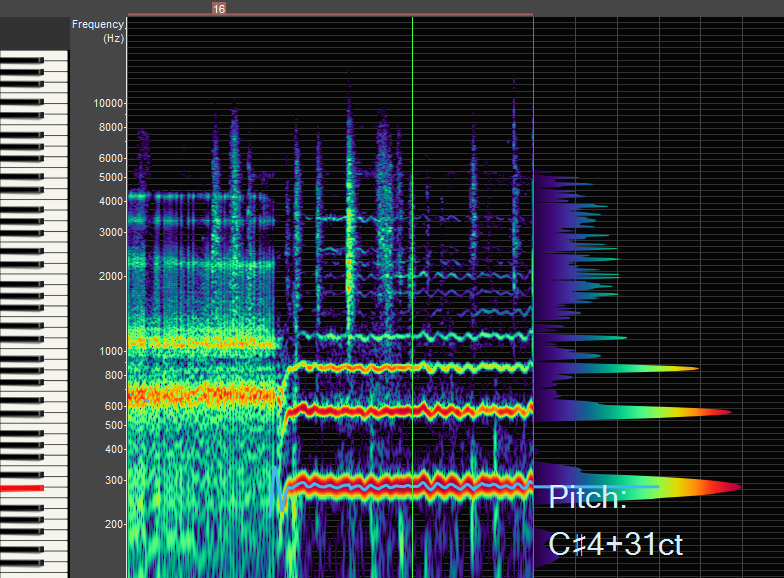
F1 sits above H2, thereby creating "open timbre." Describing this first energy boost resonant strategy as an F1/H2-H3 "acoustic mix" speaks directly to the relationship between the first energy boost and the harmonics it energizes. By comparison, "open timbre" can be applied to many different first energy boost relationships.
|
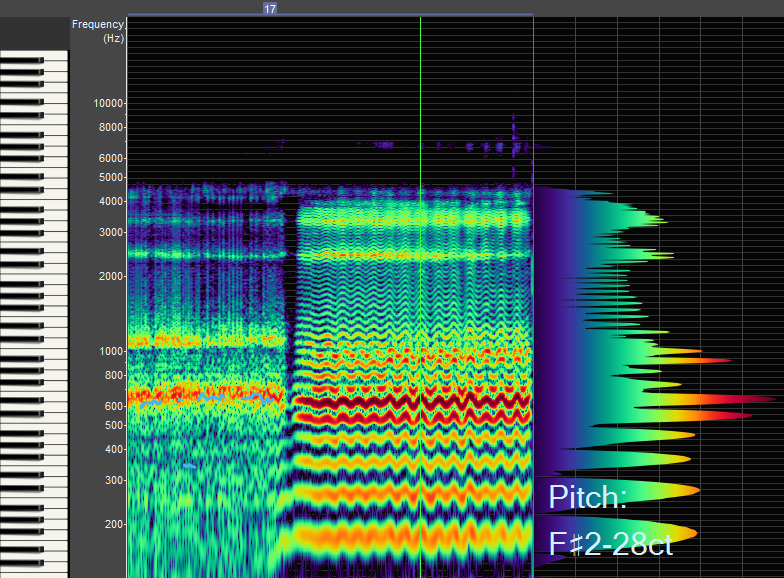
F1 sits above H2 in this image as well, but note how different this "open timbre" is to the center image. F1 coupled with H6 creates a "hey" sound and experience that is different from "acoustic mix" created by F1 sitting between the H2 and H3, even though in traditional language, both are defined with the same "open timbre" designation.
|
Speaking to what exists rather than through traditional language metaphor,
and to acoustics rather than physical manipulation
The close/mid/open IPA designations refer to specific adjustments in the vocal tract. To this end, they can be helpful in designating vowel shapes. However, vowel shape and vowel perception exist separately from one another, as we know from Ian Howell’s work. Therefore, there are different possible shapes available for creating each perceived vowel because we perceive vowel as a complex of frequency interactions. Depending on the frequencies that exist within a given sound, the vowel perception will change. A clear example exists when a vocalist sings an [u] vowel on C6 (“high C”) at 1046HZ. The frequencies that create an [u] vowel perception exist below 500HZ. This means that there are no ~u-like frequencies at 1046HZ and above. A singer can use the [u] vowel shape (e.g. in IPA, a “close/back/protruded” vowel shape), but no matter what they do, they can’t create an ~u sound, because they don’t have access to those vowel sounds. This also puts to rest the belief that each vowel sound derives from a specific physical posture. In reality, many postures exist to create any vowel perception. Further, vowel perception is somewhat dependent upon the frequencies being spoken or sung.
and to acoustics rather than physical manipulation
The close/mid/open IPA designations refer to specific adjustments in the vocal tract. To this end, they can be helpful in designating vowel shapes. However, vowel shape and vowel perception exist separately from one another, as we know from Ian Howell’s work. Therefore, there are different possible shapes available for creating each perceived vowel because we perceive vowel as a complex of frequency interactions. Depending on the frequencies that exist within a given sound, the vowel perception will change. A clear example exists when a vocalist sings an [u] vowel on C6 (“high C”) at 1046HZ. The frequencies that create an [u] vowel perception exist below 500HZ. This means that there are no ~u-like frequencies at 1046HZ and above. A singer can use the [u] vowel shape (e.g. in IPA, a “close/back/protruded” vowel shape), but no matter what they do, they can’t create an ~u sound, because they don’t have access to those vowel sounds. This also puts to rest the belief that each vowel sound derives from a specific physical posture. In reality, many postures exist to create any vowel perception. Further, vowel perception is somewhat dependent upon the frequencies being spoken or sung.
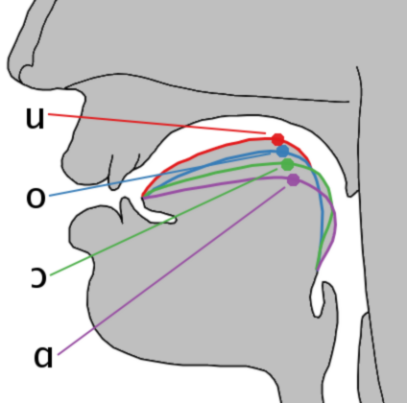
Jones, Daniel. (1972). An outline of English phonetics (9th ed.). Cambridge: W. Heffer & Sons Ltd.
The open and close tongue position idea offers the vocalist a two-toned opportunity to track vowel shape. As Ken Bozeman defines it, the open vowel shapes create specific sensational feedback, trackable along the hard palate, and the close vowel sensations follow similarly. Other sensational feedback models rely on this two-position model as well. The challenge here, of course, exists in overly simplifying complex acoustic and physical relationships that are often mismapped in people's experience.
The open and close timbre (acoustic strategies) concept, like the two-position tongue model, overly simplifies complex acoustic perceptions. Close timbre relates to the distinct experience of the first energy boost (formant) frequency residing between the first and second harmonics, but doesn’t leave room to define the series of variations that exist within that experience, or to define that experience at different sung frequencies throughout the range. Open timbre simply means “everything else above the second harmonic”, which also conjoins the differences between the "hey" and "acoustic mix" experiences. These differences are keys to creating stability and desired timbral changes. These terms existed long before contemporary voice science and neuroscience of perception existed, and are therefore understandably lacking in their ability to represent the complexity that we now understand.
The open and close timbre (acoustic strategies) concept, like the two-position tongue model, overly simplifies complex acoustic perceptions. Close timbre relates to the distinct experience of the first energy boost (formant) frequency residing between the first and second harmonics, but doesn’t leave room to define the series of variations that exist within that experience, or to define that experience at different sung frequencies throughout the range. Open timbre simply means “everything else above the second harmonic”, which also conjoins the differences between the "hey" and "acoustic mix" experiences. These differences are keys to creating stability and desired timbral changes. These terms existed long before contemporary voice science and neuroscience of perception existed, and are therefore understandably lacking in their ability to represent the complexity that we now understand.
Other options?
Simplicity through differentiation is key in helping to train the brain to create new tasks, especially with something as complex as vocal acoustics.
Focusing on physical manipulation tends to be a simplification that causes problems in body mapping and leads to a false sense of conscious control.
Simplifying complexity into two boxes, a frequently-used pedagogic tool, tends to create the inevitable add ons (e.g. there are two choices, open and close, but that one is an open/flat/rounded/back version of open, etc.), and limiting beliefs that the voice is an either/or.
Simplicity through differentiation is key in helping to train the brain to create new tasks, especially with something as complex as vocal acoustics.
Focusing on physical manipulation tends to be a simplification that causes problems in body mapping and leads to a false sense of conscious control.
Simplifying complexity into two boxes, a frequently-used pedagogic tool, tends to create the inevitable add ons (e.g. there are two choices, open and close, but that one is an open/flat/rounded/back version of open, etc.), and limiting beliefs that the voice is an either/or.
We prefer to focus on what we exists,
And allow terminology choices to follow and even change as needed.
And allow terminology choices to follow and even change as needed.
In the case of acoustics, perception guides physical action, so, we start and end with harmonics and how we perceive harmonics. Knowing that the tongue is front and high can be important information, but only so much as it tells us that said position will bring out higher harmonics. Knowing that the first energy boost (formant) frequency is low in pitch can be important information, first because it tells us that lower harmonics are accentuated.
We begin by talking about
Although these can be dense concepts, and difficult to speak about in depth at first, we demonstrate them in simple ways based on the information above, helping vocalists get the general idea through their experiences. We begin with the ear, through a process known as filtered listening, and fill in technical explanations after the vocalist has experienced results. We use voice analyzer software like Voce Vista and voice simulator software like Madde, and encourage exploration of vowel shapes through sung and/or spoken vowel chains and exercises that create meaningful connections between energy boosts (formants) (e.g. using [e] and [o] combination exercises because both have a similar first energy boosts (formants). These explorations and explanations give the vocalist enough information to play with their voice and train their ear and brain to differentiate between options across their range.
These approaches are experiential and directly associated with the sound and feelings they perceive, so they allow the vocalist to explore without having to first memorize a dictionary of tongue positions or feel crushed under the weight of add-on descriptors that can confuse their habit forming. With very little exposure to these concepts accompanied by focused listening, singers can begin to make resonant strategy choices logically, intuitively, and most importantly, their bodies learn essential tiny vocal tract differentiations quickly and easily.
We begin by talking about
- energy boost (formant) interaction with harmonics
- the impact of inertance
- acoustic strategy choices
- absolute spectral tone color, and
- the difference between vowel shape and vowel perception
Although these can be dense concepts, and difficult to speak about in depth at first, we demonstrate them in simple ways based on the information above, helping vocalists get the general idea through their experiences. We begin with the ear, through a process known as filtered listening, and fill in technical explanations after the vocalist has experienced results. We use voice analyzer software like Voce Vista and voice simulator software like Madde, and encourage exploration of vowel shapes through sung and/or spoken vowel chains and exercises that create meaningful connections between energy boosts (formants) (e.g. using [e] and [o] combination exercises because both have a similar first energy boosts (formants). These explorations and explanations give the vocalist enough information to play with their voice and train their ear and brain to differentiate between options across their range.
These approaches are experiential and directly associated with the sound and feelings they perceive, so they allow the vocalist to explore without having to first memorize a dictionary of tongue positions or feel crushed under the weight of add-on descriptors that can confuse their habit forming. With very little exposure to these concepts accompanied by focused listening, singers can begin to make resonant strategy choices logically, intuitively, and most importantly, their bodies learn essential tiny vocal tract differentiations quickly and easily.
